目录
回顾
上一篇文章,我们讨论了以下内容:
- 读取硬盘所需的参数设置,硬盘数据的地址由 CHS 提供,我们需要将柱面,磁头,扇区信息写入相应的寄存器
- 读取硬盘的测试数据并打印
- 32 位模式提供虚拟内存,分页等更加灵活高效的内存管理模式,同时增加了内存寻址的空间,寄存器也从 16 位扩展到了 32 位
- 无论计算机的显示设备多么高级,在计算机启动时,都处于 VGA 模式
- VGA 文本模式的一种,是 80x25 的行列模式,每个字符的像素大小是 9x16
- VGA 模式下,一个字符的在内存中的位置被称为字符单元
- 显示设备是内存映射设备,我们在显示设备的内存地址写入信息,就可以显示在屏幕上
- 全局描述符是 32 位模式下内存寻址重要信息
- 在 32 位模式下,段寄存器指向的不是段内存的基址,而是 GDT 中的段描述符
- 段描述符包含了段内存的基址,大小,权限等信息
- 切换到 32 位之前,我们必须定义 GDT 和 GDTD(GDT Descriptor)
- 我们还需要禁用中断,将 GDTD 交给 CPU,设置 cr0 寄存器的第一个 bit,做一个 far jump 清空 CPU pipeline
- 切换到 32 位之后,要在代码中使用 bits 32 来让 assembler 以 32 位模式编译指令,另外,我们需要将其他段寄存器指向我们新的段内存,并更新栈的地址到空闲内存地址
在读到原书关于内核这个章节的时候(第 5 章),我感觉到原书的内容开始有些不太清晰。有些地方讲复杂了,有些地方又解释不够。所以,如果有读者在读原书,那么可以结合我这个系列的 0x300 这一章节做解惑和补充。
今日目标
激动人心的时候到了,我们终于碰触到了操作系统最核心的内容——内核。
今天开始,我们将用 C 语言,开始像搭乐高积木一样,慢慢组装一个简易的操作系统。
文章很长,但是因为每个概念都具有连续性,我觉得分开写并不好,读者会忘记之前的内容,又返回去看一遍之前的文章是一种时间上的浪费。因此,我将必要的内容组织在一起,需要大家有一点耐心。
我们先预览一下本系列第 3 章会讨论的内容:
- 工具介绍,包括 gcc,ld,objdump,ndisasm 等
- C 语言的编译过程
- C 语言与汇编
- 加载内核
- Makefile
- 内核调试
在这里我想提醒一下大家,最好的学习方式就是动手实践。请大家务必动手实验,才能挖掘出更多的潜在问题,从而学习到更多的知识点。
这是我在测试的时候发现的问题。这也是为什么到加载内核的阶段,我们需要手动编译安装交叉编译器的原因之一(编译安装过程见下文)。
我的测试环境是 64 位 Ubuntu 18.04,我写了一个测试程序,只有一个函数定义。
test.c
int main()
{
return 0;
}# 系统自带的 gcc 生成 obj
gcc -ffreestanding -c test.c -o test.o然后使用:
# 系统自带的 linker 链接生成 bin 文件
ld -o test.bin -Ttext 0x0 --oformat binary test.o最后,使用:
# ndisasm 查看汇编
ndisasm test.bin > test.dis结果生成了一个 200 多万行的汇编指令文件。

文件中一直在循环出现 add [bx + si], al 这样的指令。
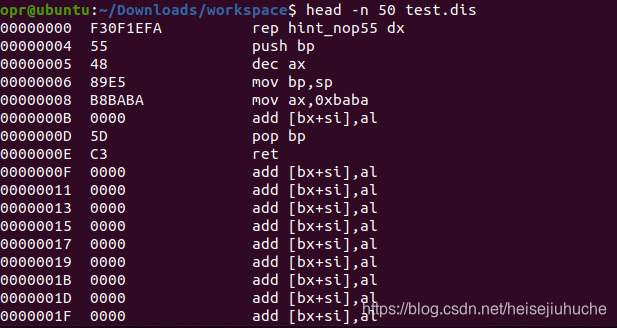
每个人的操作环境不同,我不知道 32 位系统上或者 MacOS 自带的工具是不是就能正常工作,可能还会碰到其他问题。总之,希望大家动手实践。
必要工具的安装及介绍
我们首先了解一下内核编译和加载阶段需要用到的一些工具。不是系统自带的工具,我们必须进行编译、安装。
工具一览
这些工具和库包括:
编译、链接工具
- gcc
- ld
- nasm
反汇编工具
- ndisasm
以及编译测试代码时需要用到的工具包
- binutils
工具介绍
回忆之前,我们使用 nasm 编译汇编代码,生成 .bin 文件,然后使用 qemu 做测试。并使用 od 查看原始机器码。我们能直接操作内存,这是汇编提供的最底层的能力。
现在,我们进入了可以使用 C 语言的阶段。我们有必要了解 C 语言与汇编的关系。我们需要知道 C 语言编译之后,会生成什么样的汇编代码,同时要了解 C 代码在执行的时候,内存中发生了什么变化。
有了这些需求,我们先来了解一下将会用到的工具,之后我们将简单讨论一下 C 的编译过程,让大家理解这些工具的背后逻辑。
GCC
我们将用 C 语言编写内核,那么编译 C 语言就会用到众所周知的工具 gcc。
我们即将使用以下命令来编译我们的内核:
gcc -ffreestanding -c kernel.c -o kernel.o我们看一下每个参数的作用:
- -c - 告诉编译器不要链接目标文件
- -o - 输出文件的文件名
- -ffreestanding - 见下文
gcc 在编译内核的时候,提供了一个 freestanding 的参数,用于编译内核这样的独立模块。为了更好理解这个参数,我们需要看一下 ISO C 标准中的两种 C 程序实现环境。
Hosted Environment
Hosted Env,指的是能够使用所有标准库文件或者三方库文件,并且程序启动(startup)是从 main 函数开始的程序环境。
我们在操作系统上写的任何依赖于现有操作系统资源的程序,都处于 Hosted Env(暂译为宿主环境)。
Freestanding Environment
相对于 Hosted Env,另一种环境是 Freestanding Env。在该环境下,只提供了一些标准库文件的支持,如 <float.h>,<limits.h>,<stdarg.h>,<stddef.h>等。这种只有少许标准库支持的,并且程序启动(startup)和终结(termination)都必须手动控制的程序环境,就是 Freestanding Env(暂译为独立环境)。
我们在后面的实践中会遇到,内核的执行不是从 main 函数开始,而是从程序第一个定义的函数开始执行。我们需要手动定义内核程序的入口。
关于 GCC 按编程语言分类的参数,可以参考这篇文章。
Linker
链接器的介入,其实已经到了编译的最后阶段。链接器的作用是找到函数的定义,然后将涉及到的函数调用全部拷贝到最后的可执行文件中,或者将函数的内存地址写入到可执行文件中,让程序在运行时调用。
下面,我们会讲到 C 语言的编译过程,会对 Linker 做更多说明。
C 语言编译(gcc 的临时文件)
我们所编译 C 语言,如果大家指的是 Compiling 这个动作,那么就已经到了编译的第二步。我们从头开始回顾一下编译的全过程。
C 程序的编译过程主要分为四步:
- 预编译(Pre-processing)
- 编译(Compiling)
- 汇编(Assembly)
- 链接(Linking)
开始之前,我们写一个很简单的 C 程序,然后使用一些参数来编译,保存每一步的临时文件。
我们的 C 程序包含一行注释;包含 stdio.h 头文件;定义了一个宏 sum,用于两个数字相加;又在条件编译中定义了另一个宏 BANNER,是一个字符串;然后在 main 函数中使用两个宏。
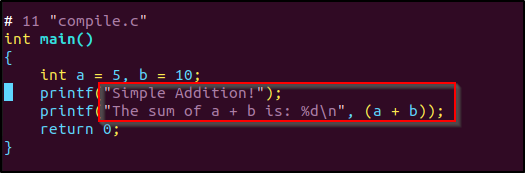
compile.c
/* I am comment and will be stripped by preprocessor */
#include <stdio.h>
// macro
#define sum(a, b) (a + b)
#ifndef BANNER
#define BANNER "Simple Addition!"
#endif
int main()
{
int a = 5, b = 10;
printf(BANNER);
printf("The sum of a + b is: %d\n", sum(a, b));
return 0;
}使用 gcc 编译,保存临时文件:
# 使用 -save-temps 保存临时文件
gcc -save-temps compile.c -o compile结果如下。
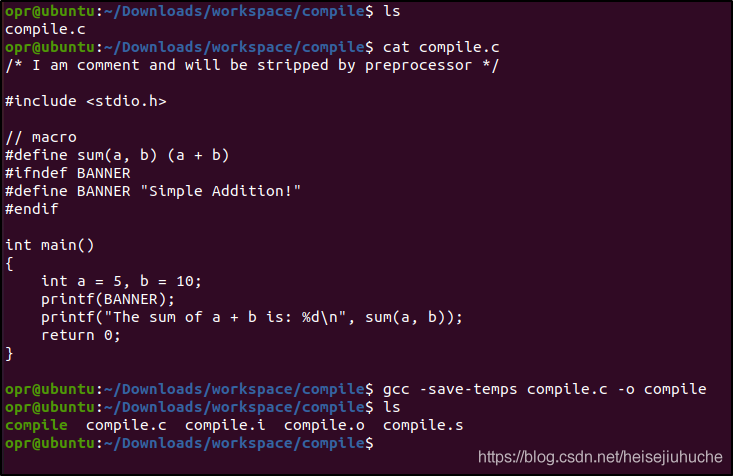
compile.i 是预处理之后生成的文件,compile.s 是编译之后生成的文件,compile.o 是汇编之后生成的文件,compile 是最终链接生成的可执行文件。
我们继续。
预处理或预编译(Pre-processing)
在这个阶段,gcc 编译工具中提供的 preprocessor,将会做 4 件事情:
- 去除注释
CPU 可不需要看注释。 - 扩展宏定义
诸如#define CIRCLEAREA(r) (3.1415 * (r) * (r)),会被相应扩展成函数调用。 - 扩展文件包含
诸如#include <stdio.h>,会被相应扩展成stdio.h的内容。 - 扩展条件编译
诸如ifdef MACRO ... endif,会被按照条件进行扩展编译。
我们来看一下 compile.i 文件中都有些什么内容。
首先,没有任何的注释信息,注释已经被 preprocessor 去除。
然后,是一大堆的头文件,从 stdio.h 扩展而来。
紧接着是大量的类型定义。
我们可以在文件的最后,找到我们的源代码。但是可以看到,所有的宏的使用,都已经替换成了宏的定义。
这就是预处理阶段,preprocessor 所进行的操作。我们进入编译阶段。
编译(Compiling)
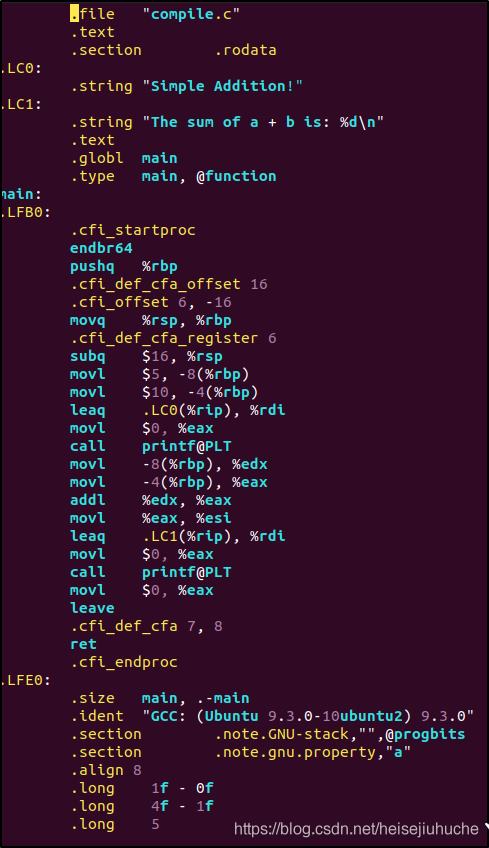
编译阶段,编译器将代码转换为汇编指令,生成 compile.s 临时文件。
我们看一下文件中包含的内容。
可以看到这就是我们的程序的汇编形式。
我尝试用 nasm 直接编译 compile.s 文件,但是会报错。这个文件的语法可能只有 gcc 工具集能认识 😂
继续下一步。
汇编(Assembly)
汇编阶段,编译器将上一步的 compile.s 文件,转换成机器码,也称 object code,生成 compile.o 文件。之前的 compile.i 和 compile.s 都是可读的 ASCII 文件,而汇编阶段生成的 compile.o 文件已经是不可读文件,我们可以看一下他的文件类型。

关于什么是 ELF 文件,可以参考 这篇文章。
不过,如果查看文件内容,还是会有一些字符串在临时文件中。

目标文件包含 object code,已经接近于一个可执行文件,但是缺最后重定位(relocation)的一步。目标文件中包含程序的元信息,即变量和函数在内存中的位置。这些变量和函数,被称为符号(symbol),被保存在一个被称为符号表(symbol table)的数据结构中。目标文件将告诉链接器如何定位函数在内存中的位置。
除此之外,目标文件还可以包含程序的调试信息,例如在使用 gcc 编译的时候,指定 -g 参数。然后在用 ld 链接的时候,不要指定 --oformat 参数,即可在目标文件中包含调试信息(调试信息其中一项就是符号表,后面会讲到)。
继续下一步。
链接(Linking)
最后一步链接,会将函数的实际内存地址,链接到最终的执行文件。我们看到,函数的调用在运行时,CPU 就知道到内存的什么位置,去找需要用到的函数。
我们可以看到,上一步生成的 compile.o 目标文件的文件类型是 relocatable。这之中包含了链接器可以执行的操作,relocate。
目标文件中包含三种符号(symbol):
- 已经定义的外部符号(defined external symbols),也被称为 public symbol 或者 entry symbol;可以被其他模块(目标文件)调用;理解为,定义在本目标文件之内的符号(函数名,变量名等),被其他目标文件调用
- 未定义的外部符号(undefined external symbols),对于其他目标文件内符号的引用;理解为,这些符号的定义在其他目标文件中,而本目标文件在调用他们
- 本地符号(local symbols),在本目标文件中使用的符号;理解为,在本目标文件定义,在本目标文件内调用
那么,我们再看一下什么是重定位(relocate)。
Relocate 是对内存位置极度依赖的代码的内存地址重新分配。
链接器就像一个统筹人员,他读取所有的目标文件,知道了程序需要使用的所有的符号(函数名,变量名等),然后为每一个符号分配内存地址。那么,最终所有目标文件被组装再一起的时候,就知道该到哪个内存位置,调用哪个函数。
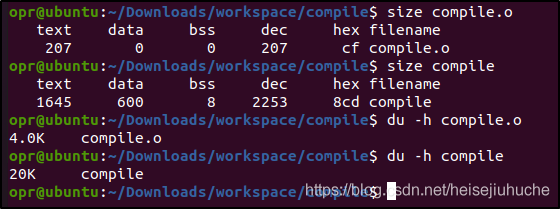
另外,链接器还会添加一些额外的代码,帮助程序正常启动和终止。我们可以查看 .o 目标文件和最终生成的可执行文件的大小。
可以看到最终的可执行文件大了很多。
关于链接,还有动态和静态两者之分。这里不再展开了。大家想要了解,可以看这篇文章,这篇文章,还有这篇文章。
我们即将使用如下命令来链接目标文件:
ld -o test.bin -Ttext 0x0 --oformat binary test.o我们看一下每个参数的作用:
- -o - 输出文件的文件名
- -Ttext - 如之前 Boot Sector 中的 org 指令,定义我们的内核代码将被加载到内存的哪个位置
- --oformat binary - 设置以二进制的形式输出最终文件,支持的所有输出格式可以使用
objdump -i查看
下面我们继续看一下程序编写过程中其他工具的介绍。
Objdump
objdump 可以用于查看 .bin 文件的机器码内容,同时也可以查看 .o 目标文件的汇编代码,只需要使用 -d 参数即可。
objdump -d filename.oNasm
用于编译加载内核的 Boot Sector。
nasm 又很多的输出格式。在这篇文章之前,我们生成的都是 .bin 文件。
这里,我们会在 指定内核入口 一节中,将源文件编译成一个 .o 目标文件,之后跟内核的 .o 文件链接到一起。
Ndisasm
反汇编工具。可以将二进制文件反编译成汇编指令。
# 以 32 位反汇编
ndisasm -b 32 filename.bin
# 或者
ndisasm -u filename.binCross-compiler
我们看一下工具链的最后一个环节,交叉编译器(Cross-compiler)。
为什么我们需要交叉编译器,大家可以看这篇文章。
疑问
我对于为什么要用交叉编译目前还没有太理解。因为无论我使用系统自带的 64位 gcc 和 ld 去编译、链接,还是使用 32 位的交叉编译去编译和链接,生成的最终文件都可以在qemu-system-i386和qemu-system-x86_64上运行。编译出 32 位文件可以运行在 64 位环境我理解,有向上兼容。但是编译出 64 位文件可以在 32 位环境运行,就有点无法理解了。这个问题抛出来,有待研究。
不过我们即将使用 32 位交叉编译去测试所有的代码,第一,为了降低复杂度。我不想给自己增加负担,参照原书先理解 32 位环境,64 位留作进阶。第二,为了解决文首所说的ndisasm反汇编 64 位的目标文件时,会出现大量重复汇编指令的问题。
Debian 系列 Linux 之外的系统,Cross-compiler 的编译和安装参考这篇文章。
Debian 系列的 Linux 可以按照下面总结的步骤,进行 Cross-compiler 的编译和安装。
首先下载 Binutils 和 GCC 的源码,下载地址:
- binutils - http://ftp.gnu.org/gnu/binutils/
- gcc - http://ftp.tsukuba.wide.ad.jp/software/gcc/releases/
安装依赖:
sudo apt install build-essential bison flex libgmp3-dev libmpc-dev libmpfr-dev texinfo -y设置环境变量:
export PREFIX="$HOME/opt/cross"
export TARGET=i686-elf
export PATH="$PREFIX/bin:$PATH"编译安装 Binutils:
cd $HOME/src
mkdir build-binutils
cd build-binutils
../binutils-x.y.z/configure --target=$TARGET --prefix="$PREFIX" --with-sysroot --disable-nls --disable-werror
make
make install编译安装 GCC:
cd $HOME/src
# The $PREFIX/bin dir _must_ be in the PATH. We did that above.
which -- $TARGET-as || echo $TARGET-as is not in the PATH
mkdir build-gcc
cd build-gcc
../gcc-x.y.z/configure --target=$TARGET --prefix="$PREFIX" --disable-nls --enable-languages=c,c++ --without-headers
make all-gcc
make all-target-libgcc
make install-gcc
make install-target-libgcc现在,就可以使用 ~/opt/cross/bin 下的 i686-elf-gcc/ld 来编译和链接目标文件了。
C 与汇编
之前的文章中,我们直接使用汇编编写 Boot Sector。
现在,虽然我们有了更高级的 C 语言,但同时,我们也必须了解 C 语言与汇编的紧密联系。
其实细想这里面的对应关系,没有想象那么复杂。
我们可以把一个 C 程序按功能大致分为:
- 变量定义(局部变量)
- 条件判断
- 循环
- 函数调用(函数参数,函数返回值)
- 指针
而在理解 C 程序与汇编的转换的时候,最重要的是,要理解栈是如何生成,运用并销毁的。
接下来我们要做的就是写 5 个简单的 C 程序,包含这 5 个方面。然后,通过 ndisam 查看程序的汇编指令,来理解每一个功能是如何在汇编中实现的。
如果你还没有交叉编译器,参见前文 Cross-compiler 一节。
另外,建议大家先阅读我逆向系列文章第三篇中的 为什么程序会有栈? 以及 为什么 EBP 和 EIP 会在 BoF 中被覆盖? 这两个小章节。那里讲了栈的作用以及 C 函数调用时栈的变化情况,提及了函数序言等必要概念。
局部变量
首先,我们看一下局部变量在汇编中的实现。
写一个简单的 local_var 程序,只有一个函数定义,函数中包含一个局部变量 var, 然后直接 return 这个变量。
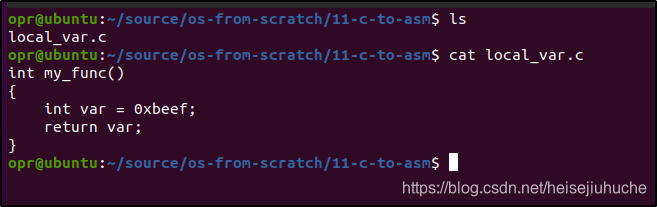
交叉编译一下,然后用 ndisasm 查看汇编。
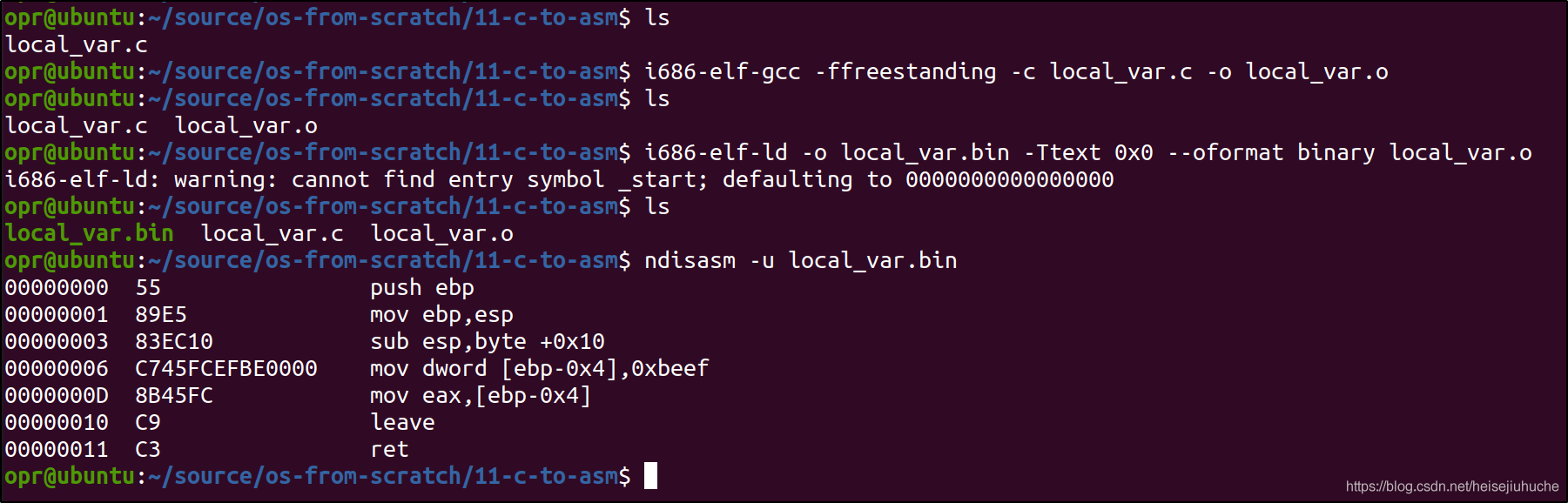
00000000 55 push ebp
00000001 89E5 mov ebp,esp
00000003 83EC10 sub esp,byte +0x10
00000006 C745FCEFBE0000 mov dword [ebp-0x4],0xbeef
0000000D 8B45FC mov eax,[ebp-0x4]
00000010 C9 leave
00000011 C3 ret任何 C 函数定义在汇编中都以前三行函数序言(Function Prologue)开始,分配一个栈空间(栈帧)给指定函数。
32 位 C 程序使用 4 个字节存储 int 类型的变量。因此可以看到第 4 行,0xbeef 被存储到 ebp - 0x4 的内存地址上。
函数的返回值,会被存储到 eax 中。因此,第 5 行,将 ebp - 0x4 位置上的数据,写入到 eax 寄存器中。
最后,调用 leave ret 结束该函数调用。
如果大家看了 0x03-逆向-BoF基础的基础 一文,就能知道汇编指令 leave 和 ret 的时候做了哪些额外的操作。
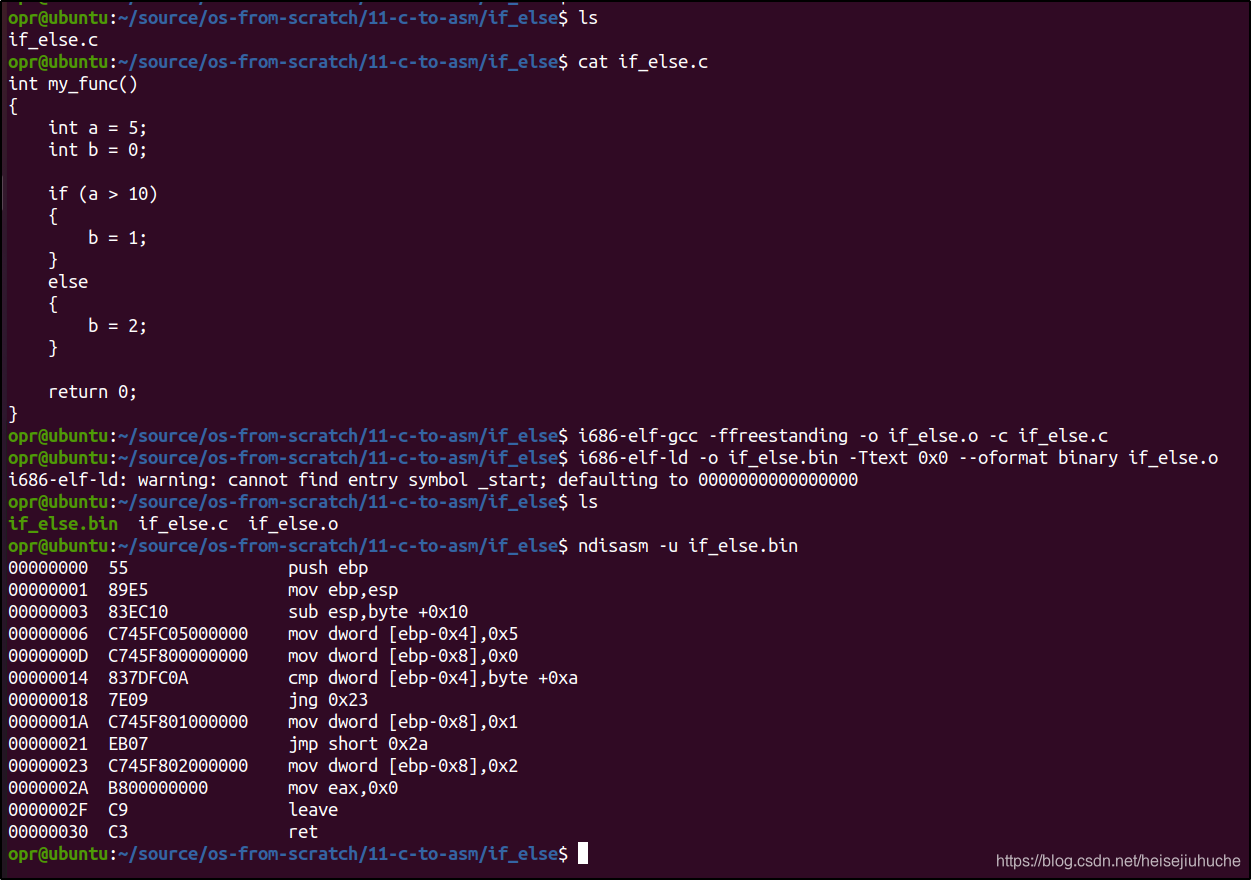
条件判断
00000000 55 push ebp
00000001 89E5 mov ebp,esp
00000003 83EC10 sub esp,byte +0x10
00000006 C745FC05000000 mov dword [ebp-0x4],0x5
0000000D C745F800000000 mov dword [ebp-0x8],0x0
00000014 837DFC0A cmp dword [ebp-0x4],byte +0xa
00000018 7E09 jng 0x23
0000001A C745F801000000 mov dword [ebp-0x8],0x1
00000021 EB07 jmp short 0x2a
00000023 C745F802000000 mov dword [ebp-0x8],0x2
0000002A B800000000 mov eax,0x0
0000002F C9 leave
00000030 C3 ret
可以看到,函数序言是一样的,分配了一个栈空间。
这段代码里有两个变量,a,和 b。因此,第 4 第 5 行,分别分配了 4 个字节的空间给两个变量,并将初始值 5 和 0 写入到相应的地址。
第 6 行,cmp 命令比较 ebp - 0x4 内存地址中的值(变量 a,初始值为 5)与 0xa (十进制 10)的大小。
如果变量 a 的值小于 10,执行第 7 行的指令,跳转到偏移量为 0x23 的位置上,也就是第 10 行指令,将 2 写入到 ebp - 0x8 的内存位置中(变量 b 存储的内存地址),变量 b 被赋值为 2。
如果变量 a 的值大于等于 10,执行第 8 行指令,将 b 赋值为 1。
然后执行第 9 行指令,跳转到偏移量为 0x2a 的内存位置,将返回值 0 写入到 eax 寄存器中。
最后调用 leave ret 结束函数调用。
关于汇编的条件指令,看 这篇文章。
循环
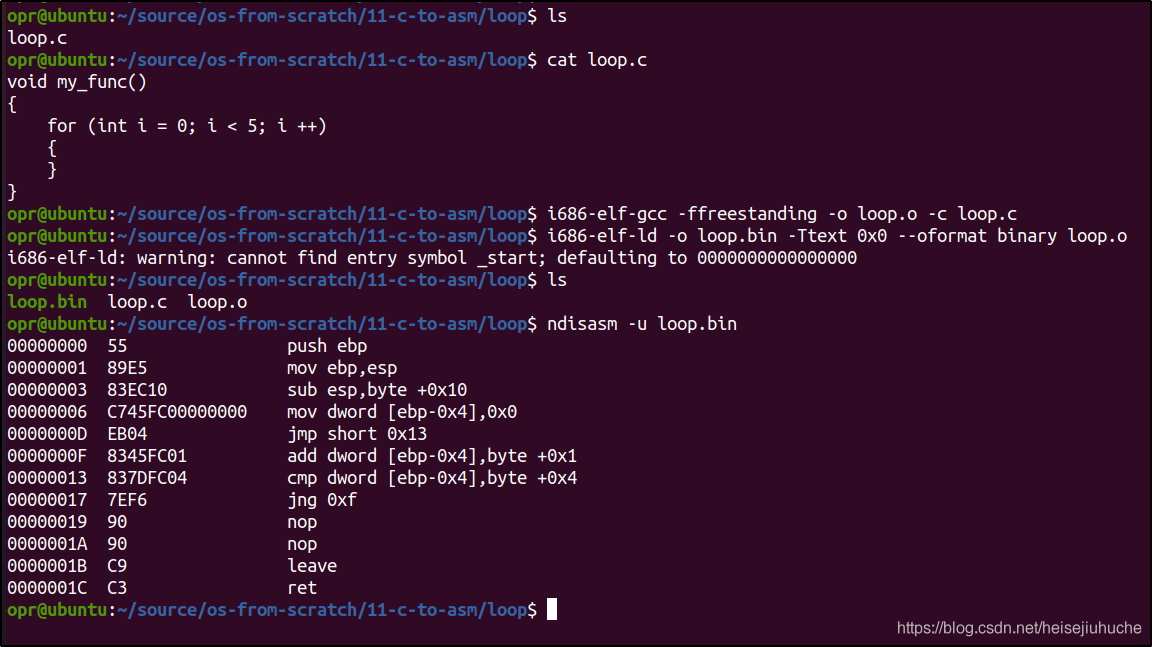
00000000 55 push ebp
00000001 89E5 mov ebp,esp
00000003 83EC10 sub esp,byte +0x10
00000006 C745FC00000000 mov dword [ebp-0x4],0x0
0000000D EB04 jmp short 0x13
0000000F 8345FC01 add dword [ebp-0x4],byte +0x1
00000013 837DFC04 cmp dword [ebp-0x4],byte +0x4
00000017 7EF6 jng 0xf
00000019 90 nop
0000001A 90 nop
0000001B C9 leave
0000001C C3 ret
第 4 行分配 4 个字节给变量 i,并写入初始值 0 到 ebp - 0x4 的内存位置上。
第 5 行跳转到偏移量为 0x13 的内存地址,也就是第 7 行。
第 7 行比较 ebp - 0x4 内存地址上的值(也就是变量 i)与 4 的大小。
如果小于 4,执行第 8 行指令,跳转到偏移量为 0xf 的内存位置上,也就是第 6 行。
第 6 行将 ebp - 0x4 内存地址上的值(也就是变量 i)加 1。
然后又执行第 7 行的比较指令,这样跳转循环,直到 ebp - 0x4 内存位置上的值等于 4,调用 leave ret,结束函数调用。
函数调用
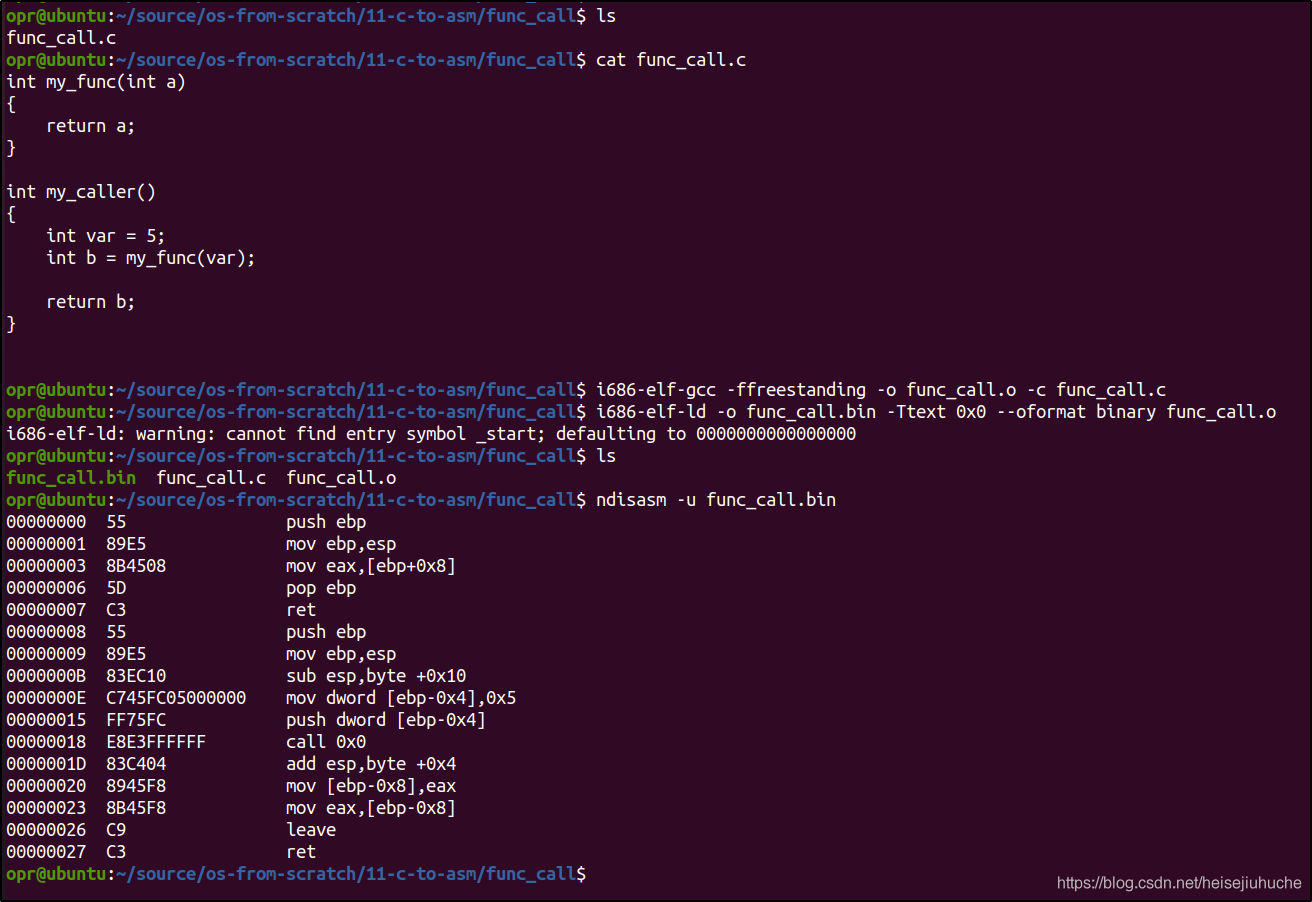
我们写了两个函数。第一个函数接受一个 int 类型参数,然后返回该参数。第二个参数调用第一个函数,传递一个变量 var 给第一个函数,并将返回值赋值给变量 b。
00000000 55 push ebp
00000001 89E5 mov ebp,esp
00000003 8B4508 mov eax,[ebp+0x8]
00000006 5D pop ebp
00000007 C3 ret
00000008 55 push ebp
00000009 89E5 mov ebp,esp
0000000B 83EC10 sub esp,byte +0x10
0000000E C745FC05000000 mov dword [ebp-0x4],0x5
00000015 FF75FC push dword [ebp-0x4]
00000018 E8E3FFFFFF call 0x0
0000001D 83C404 add esp,byte +0x4
00000020 8945F8 mov [ebp-0x8],eax
00000023 8B45F8 mov eax,[ebp-0x8]
00000026 C9 leave
00000027 C3 ret
前 5 行,是第一个函数 my_func 的汇编形式。
第 3 行中,该函数将 ebp + 0x8 内存内存位置上的内容写入 eax 寄存器,作为返回值。
第 6 行开始,是第二个函数调用第一个函数的汇编实现。
第 9 行,将 5 写入 ebp - 0x4 的内存地址(var 变量)。
第 10 行将 var 变量存入栈中,由于 push 指令先将 esp - 4,因此当前 esp 应该在 ebp - 0xc 的位置上(0x10 - 0x4)。
第 11 行,call 指令调用内存偏移量为 0x0 位置上的函数,也就是 my_func 函数。
第 2 行,my_func 函数中,将 esp 的值写入了 ebp,也就是说,当前 ebp 指向 ebp - 0xc 。
第 3 行,my_func 函数中,将 ebp + 0x8 内存位置上的值,写入 eax 寄存器,作为返回值。
因为当前 ebp 指向 ebp - 0xc,那么 ebp + 0x8 也就等于 ebp -0x4。在 ebp - 0x4 位置上的,是我们的变量 var,因此写入 eax 寄存器作为返回值的,就是我们传递给第一个函数的 var 变量。
指针
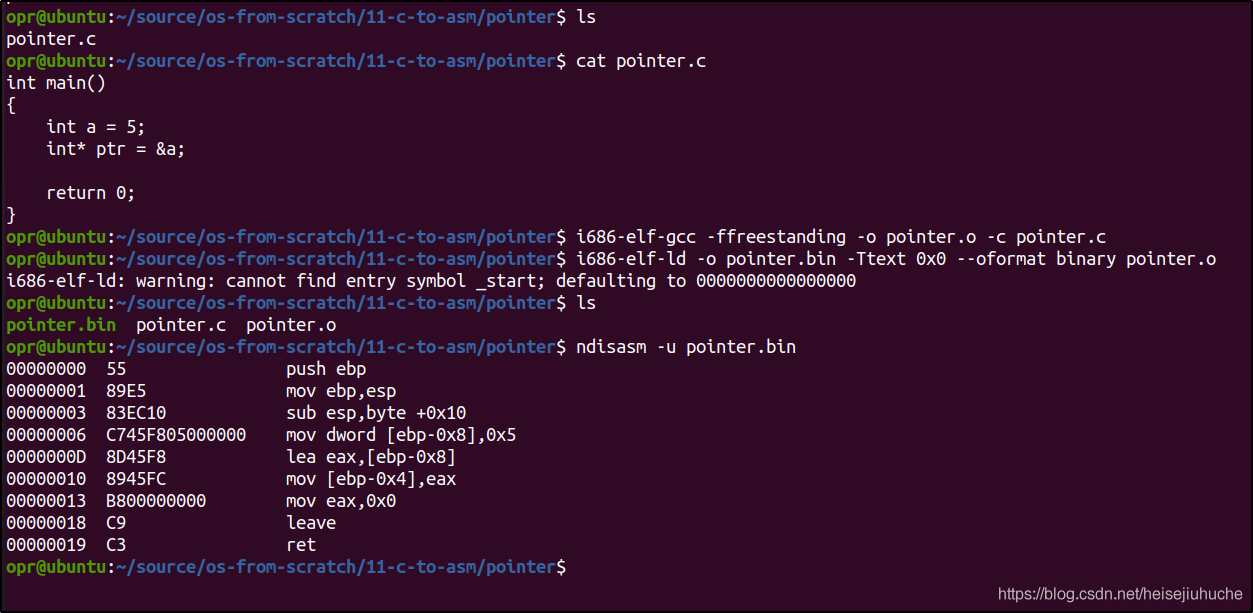
00000000 55 push ebp
00000001 89E5 mov ebp,esp
00000003 83EC10 sub esp,byte +0x10
00000006 C745F805000000 mov dword [ebp-0x8],0x5
0000000D 8D45F8 lea eax,[ebp-0x8]
00000010 8945FC mov [ebp-0x4],eax
00000013 B800000000 mov eax,0x0
00000018 C9 leave
00000019 C3 ret
第 4 行,将 5 写入 ebp - 0x8 的内存位置。
第 5 行,lea(load effective address) 指令将 ebp - 0x8 位置上的值的内存地址,写入 eax 寄存器。
第 6 行,将 eax 写入到 ebp - 0x4 的内存位置上。
第 7 行,将 0 写入 eax 作为返回值。
最后结束函数调用。
疑问
一个指针是 8 个字节。如果第 4 行变量a被写入到ebp - 0x8的位置上,而第 6 行将eax写入到ebp - 0x4的位置上,岂不是会覆盖掉变量a的值。
猜想可能是编译器内部的优化。因为它知道在指针赋值之后,没有任何代码需要引用变量a,因此覆盖其值也没事,节省内存空间。可以再写一个int b = a; *ptr = &b;来观察汇编的实现。
指针这一特性的汇编实现,我们需要了解的是第 5 行 lea 指令,会将我们变量的地址,写入到寄存器。
加载内核
现在,我们将加载一个极其简单的内核。这个内核往显示设备内存中写入一个 X 字符。
我们将用交叉编译器 i686-elf-gcc 和 i686-elf-ld 完成 C 程序的编译,用 nasm 完成 boot sector 的编译,最后用 cat 命令将两个二进制文件写入到一个文件中(os-image),最后用 qemu 测试。
如果在测试当中报出 Disk load error,可以尝试调整磁盘参数(第一个软盘是 0x0,第一块硬盘是 0x80),或者,在 qemu 上加上 -fda 参数。
另外,我们将分两种模式来编译,一种使用手动编译,另一种使用 Makefile 来自动化编译的过程。
手动编译
代码在这里可以找到 Simple Kernel。
首先,一个新的汇编指令:
- equ
equ 用于定义常量,可以看到我们将常量名按惯例全部大写:
KERNEL_OFFSET equ 0x1000再来看一下我们的内核文件:
void main()
{
char* video_memory = (char*)0xb8000;
*video_memory = 'X';
}我们之前讲过,内核编译处于 freestanding 模式,所以,这个函数名,不一定是 main,可以是任意合法的函数名。
这个简单内核,将用 C 语言完成在屏幕左上角显示字符 X 的功能。
回忆上一篇文章,32 位模式调用显示设备(内存映射型设备)显示字符,就是往显示设备内存地址中写入数据即可。
我们来看一下这个程序的汇编实现。
00000000 55 push ebp
00000001 89E5 mov ebp,esp
00000003 83EC10 sub esp,byte +0x10
00000006 C745FC00800B00 mov dword [ebp-0x4],0xb8000
0000000D 8B45FC mov eax,[ebp-0x4]
00000010 C60058 mov byte [eax],0x58
00000013 90 nop
00000014 C9 leave
00000015 C3 ret
有了之前对指针汇编实现的理解,这个内核的汇编实现就非常简单了。
第 4 行将显示设备内存地址 0xb8000 写入栈中。
第 5 行将这个内存地址再写入 eax 寄存器中。
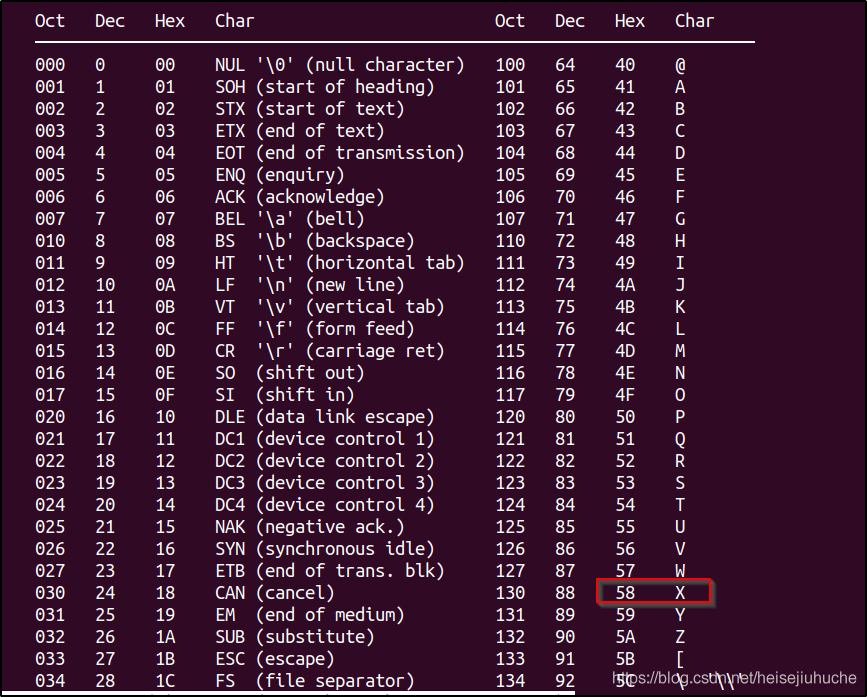
第 6 行,往 eax 所指向的内存地址中写入 0x58。
0x58,即 X 的十六进制 ASCII 码。
现在,可以开始编译了。
# 编译内核
i686-elf-gcc -ffreestanding -o kernel.o -c kernel.c
# 链接生成二进制文件 kernel.bin
i686-elf-ld -o kernel.bin -Ttext 0x1000 --oformat binary kernel.o
# 编译 boot sector
nasm -fbin boot_sector.asm -o boot_sector.bin
# 将两个 bin 文件合并
cat boot_sector.bin kernel.bin > os-image
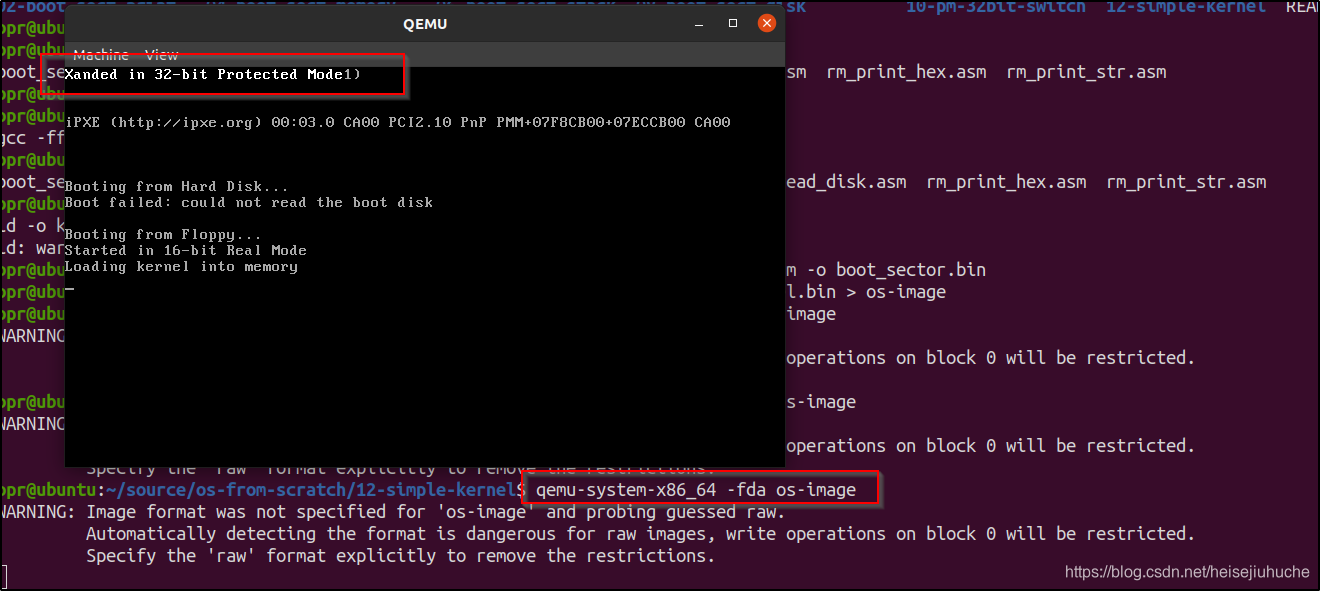
# 测试
qemu-system-i386 -fda os-image如果在 qemu 屏幕的左上角看到如下字符,说明第一个内核加载并执行成功。
指定内核入口
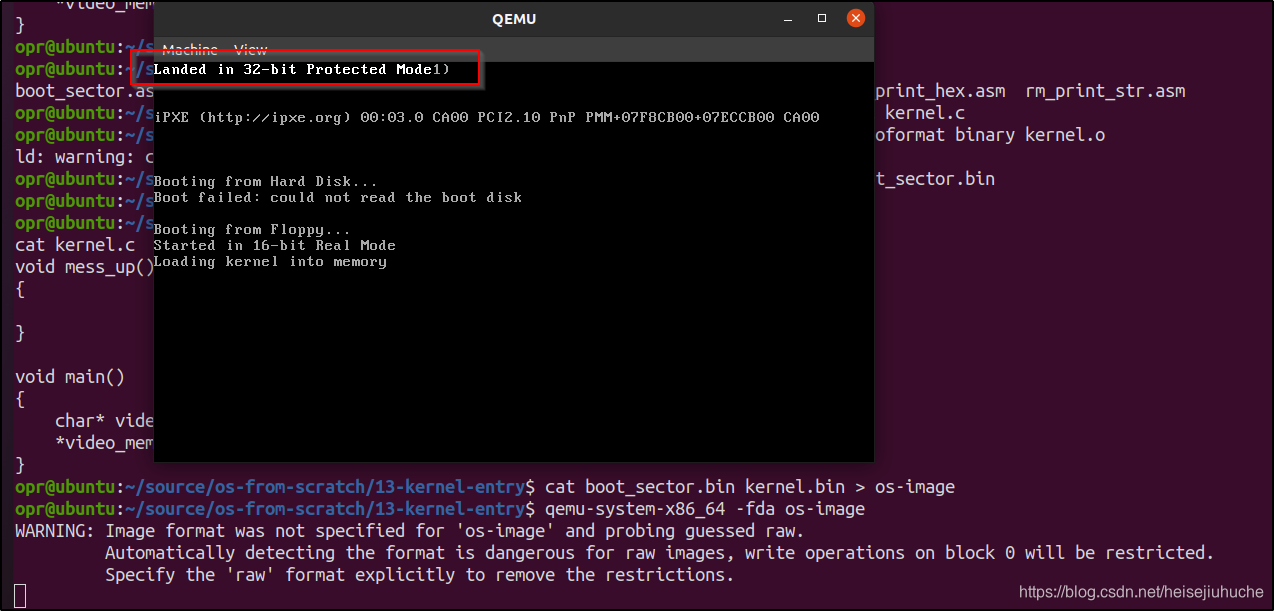
我们的内核处于 freestanding 模式,意味着默认情况下,内核程序没有 main 函数这样的入口。如果我们尝试在当前内核函数的上方再定义一个空函数,那么字符将无法显示。
void mess_up()
{
}
void main()
{
char* video_memory = (char*)0xb8000;
*video_memory = 'X';
}
并没有字符 X 输出。
由于我们在链接的时候指定了 -Ttext 参数,告诉编译器跳转到指定的地址去执行内核代码。CPU 跳转到指定地址之后,就会从内核的第一行指令开始执行。
而我们看过函数调用的汇编实现。每个函数调用结束的时候,都有一个 ret 指令,用于退出当前函数。
那么,CPU 就会从 Boot Sector 跳转到我们的内核,执行第一个空函数,然后执行到 ret 指令,返回到 Boot Sector 继续执行。所以 main 函数永远不会执行。
现在,我们必须告诉编译器,我们内核程序的入口在哪里。
extern 指令
这一小节的代码可以在这里找到 Kernel Entry。
编译过程中,我们提到了符号(symbol)。每一个函数名,变量名,都是一个 symbol。
链接的过程当中,链接器会确定这些符号实际的内存地址。
extern 命令,就可以告诉链接器,将指定符号替换成实际内存地址。
下面是 kernel_entry.asm 的代码:
[bits 32]
[extern main]
call main
jmp $
拆解一下:
- 我们已经处于 32 位模式
- 内核入口函数,这里为 main(替换成对应的内核函数名)
- 调用 main 函数
- 从 main 函数返回之后,挂起(可以不需要这行代码,自行测试)
现在,需要首先将 kernel_entry.asm 编译成目标文件:
# 指定 elf 格式输出可重定位目标文件,用于和 kernel.o 一起链接
nasm -felf kernel_entry.asm -o kernel_entry.o在链接的时候,要加入 kernel_entry.o:
i686-elf-ld -o kernel.bin -Ttext 0x1000 --oformat binary kernel_entry.o kernel.o其他步骤照旧。这样,我们就可以准确找到指定的内核代码,显示出字符 X。
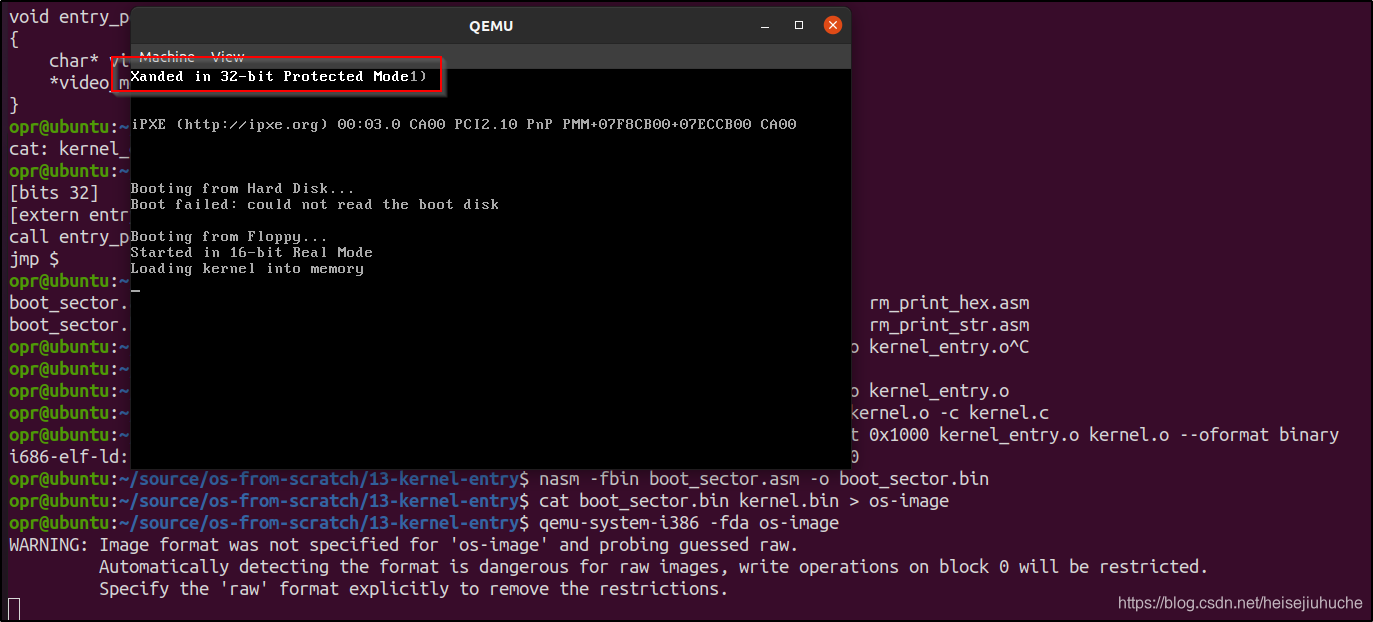
Makefile
每次都手动编译每一个目标文件,再链接,再合并,非常麻烦。
我们将使用 make 来自动化编译过程。
make 需要一个配置文件,称为 Makefile。
下面我们就讨论一下如何使用 Makefile 自动化整个编译过程。
Makefile 可以让我们指定一个源文件该如何编译,需要哪些依赖。我们通过在 Makefile 中编写一系列的规则,来让 make 帮助我们自动化编译的过程。同时,make 将只更新必要的文件,而不会去编译没有改动的文件。
关于 Makefile 的一切,看 这里。
基本规则
最简单的规则:
[目标(taget)]: [源/依赖(source-file/dependency)]
[编译命令(compile command)]
# 例子
kernel.o: kernel.c
gcc -ffreestanding -c kernel.c -o kernel.o确保 kernel.c 和 Makefile 在同一文件夹。那么就可以使用
make kernel.o来编译内核的目标文件,再也不需要输入冗长的命令了。
我们可以照样加入其他文件的编译代码:
kernel.bin: kernel_entry.o kernel o
i686-elf-ld -o kernel.bin - Ttext 0x1000 kernel_entry.o kernel o -- oformat binary
kernel.o: kernel.c
i686-elf-gcc - ffreestanding -c kernel .c -o kernel.o
kernel_entry.o: kernel_entry.asm
nasm kernel_entry.asm -f elf -o kernel_entry.o特殊变量
Makfile 提供了一些特殊变量来简化规则编写。
这些特殊变量包括:
$@- 目标的文件名;比如kernel.o: kernel.c,那么$@可以用来代替kernel.o$<- 第一个源文件/依赖的文件名;比如kernel.o: kernel.c,那么$<可以代替kernel.c$^- 所有的源文件/依赖的文件名;比如kernel.bin: kernel_entry.o kernel.o,那么$^可以代替kernel_entry.o kernel.o
更多关于特殊变量的信息,可以看 这篇文章。
那么,Makefile 现在可以写成这样:
kernel.bin: kernel_entry.o kernel o
ld -o $@ - Ttext 0x1000 $^-- oformat binary
kernel.o: kernel.c
gcc - ffreestanding -c $< -o $@
kernel_entry.o: kernel_entry.asm
nasm $< -f elf -o $@默认目标与临时文件清理
代码可以在这里找到 Kernel Makefile。
当使用 make 命令而不指定目标时,Makefile 中定义的第一个目标会被选中。这个目标,也叫默认目标。
另外,我们可以定义一个目标(通常为 clean)来清理生成的临时文件(.o,.bin 等)。
现在,我们的 Makefile 如下:
all: run
kernel.bin: kernel_entry.o kernel.o
i686-elf-ld -o $@ -Ttext 0x1000 $^ --oformat binary
kernel_entry.o: kernel_entry.asm
nasm $< -f elf -o $@
kernel.o: kernel.c
i686-elf-gcc -ffreestanding -c $< -o $@
boot_sector.bin: boot_sector.asm
nasm $< -f bin -o $@
os-image: boot_sector.bin kernel.bin
cat $^ > $@
run: os-image
qemu-system-i386 -fda $<
clean:
rm *.bin *.o
我们只需要运行 make,就可以完成编译和测试的所有流程。
宏、匹配规则与通配符
这一小节的代码可以在这里找到 New Code Struct。
由于之后代码会越来越多,那么所有文件都放在一起显然难以维护。所以,我们需要重新安排一下项目的代码结构。
新的代码结构
按照原书,我们将代码分为三个模块:
- boot - 启动相关的所有代码(所有的汇编代码)
- kernel - 内核相关的所有代码(目前只有 kernel.c)
- drivers - 硬件驱动相关的所有代码(目前还没有涉及)
有了新的代码结构,那么原来的 Makefile 就不可用了。我们需要一些新的概念来让 Makefile 更可扩展,更加高效。
新的 Makefile
接下来,我们将使用宏(macro),通配符(wildcard)以及匹配规则(pattern rules)来扩展 Makefile。
关于 Makefile 的一切,看 这里。
可以根据文档理解新的 Makefile 中的内容。我把 Makefile 和注释列在下面。
# 通配符匹配文件夹中所有的 C 源文件;C_SOURCES 宏将扩展为所有的 C 源文件
C_SOURCES = $(wildcard kernel/*.c drivers/*.c)
# 通配符匹配文件夹中所有的头文件;HEADERS 宏将扩展为所有的头文件
HEADERS = $(wildcard kernel/*.h drivers/*.h)
# 通过这样的形式,将所有 C 源文件的扩展名替换为 .o,比如 kernel.c 变成 kernel.o;
# OBJ 宏将扩展为所有的 .o 目标文件
OBJ = ${C_SOURCES:.c=.o}
# 修改路径,指向你机器上编译好的交叉编译器
CC = /home/opr/opt/cross/bin/i686-elf-gcc
# 修改路径,指向你机器上的 gdb
GDB = /usr/bin/gdb
# -g: 编译时带上默认 debug 信息;debug 是分级的,更多信息大家可以参考
# https://www.rapidtables.com/code/linux/gcc/gcc-g.html
CFLAGS = -g
# 默认目标
os-image: boot/boot_sector.bin kernel.bin
cat $^ > $@
# 默认目标将运行这个 run
run: os-image
qemu-system-i386 -fda $<
kernel.bin: boot/kernel_entry.o ${OBJ}
i686-elf-ld -o $@ -Ttext 0x1000 $^ --oformat binary
# kernel.gdb 用于内核 debug,我们没有指定 --oformat 因为该参数会去除掉所有的
# debug 信息,包括符号表
kernel.gdb: boot/kernel_entry.o ${OBJ}
i686-elf-ld -o $@ -Ttext 0x1000 $^
# 启动 QEMU 并使用 -s 参数连接 gdb,-s 参数会让 qemu 监听 TCP 1234 端口,等待 gdb 连接
# 然后启动 gdb,-ex 执行命令,首先连接 1234 端口,然后加载上一步编译好的带有符号表的 debug 文件,即可开始 debug
debug: os-image kernel.gdb
qemu-system-i386 -s -fda os-image &
${GDB} -ex "target remote localhost:1234" -ex "symbol-file kernel.gdb"
# % 在这里的意思是,要编译一个 .o 文件,一定用文件名相同的 .c 文件去编译
# 比如要编译 kernel.o,那么一定要找到 kernel.c 去编译
%.o: %.c ${HEADERS}
${CC} ${CFLAGS} -ffreestanding -c $< -o $@
%.o: %.asm
nasm $< -f elf -o $@
%.bin: %.asm
nasm $< -f bin -o $@
clean:
rm -rf *.bin *.o os-image *.elf *.gdb
rm -rf kernel/*.o boot/*.bin drivers/*.o boot/*.o关于 Makefile,还是参考 这篇教程。
Debug 内核代码
随着内核代码越来越多,能够 Debug 是非常重要的。否则,出了问题却无法定位。好在 QEMU 提供了连接 GDB 的功能,让我们可以 debug 我们的内核。
接下来,我们讨论如何将 QEMU 连接到 gdb 来 debug 我们的内核代码。
QEMU 与 GDB
如果你用的是 MacOS,那么 参考这篇文章,编译 gdb。
QEMU 如何与 GDB 连接,我们在新的 Makefile 中已经提到了。
启动 QEMU 时使用 -s 参数,QEMU 会监听 TCP 1234 端口,等待 GDB 连接。
GDB 连接之后,执行 target remote 命令和 symbol-file 命令,开始 debug。
这里要注意,断点之后的函数名,是你定义在 kernel.c 中的函数名,任意合法函数名皆可。
运行 make debug:
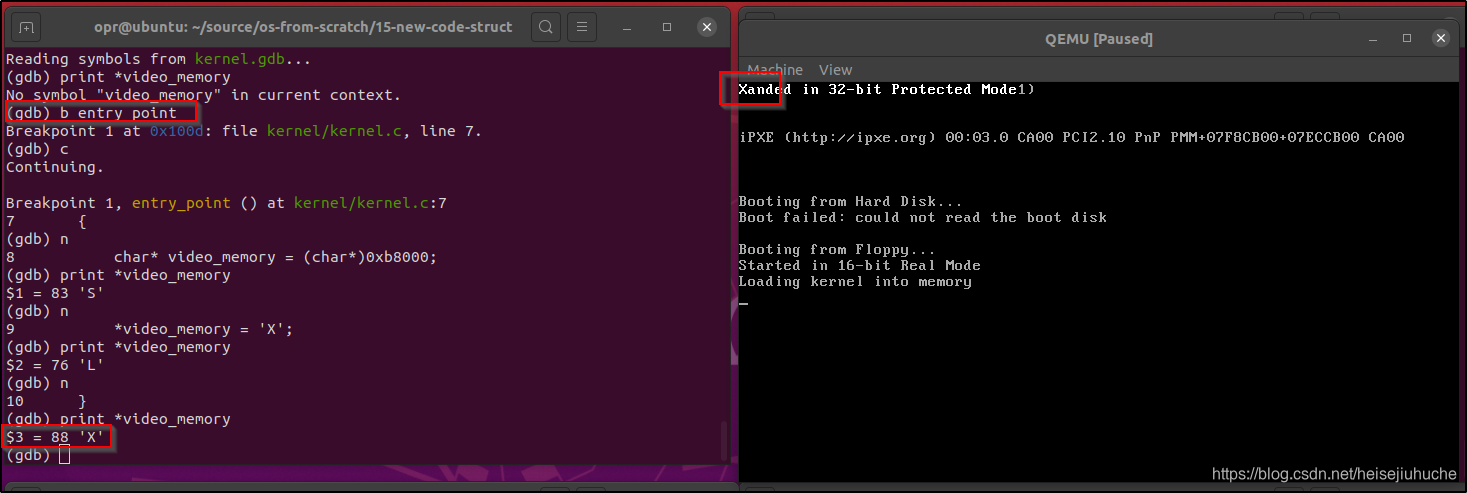
更多关于 QEMU Debug 的信息,可以参考 官方文档。
现在,我们有一个可以运行的内核,并掌握了 debug 内核代码的能力。
这就是本篇文章的全部内容。
总结
- 加载内核阶段需要用到的工具链,包括交叉编译的 gcc 和 ld,以及用于查看汇编指令的 ndisasm
- C 程序的编译可以处于两个不同的模式,一个是 Hosted Environment(宿主环境),另一个是 Freestanding Environment(独立环境)
- 独立环境下,程序没有入口,程序的启动和终结可以由程序员手动指定
- C 的编译过程有预处理,编译,汇编和链接 4 个步骤
- 讨论了 C 程序的不同功能在汇编中的实现(局部变量,条件判断,循环,函数调用以及指针)
- 通过手动编译的方式加载一个简单的内核
- 使用 Makefile 自动化编译过程
- 为了使项目更有维护性,代码被分为
boot,kernel,drivers三个模块 - 更新了 Makefile,使用宏、通配符以及匹配规则使 Makefile 可以用于新的代码结构
- QEMU 使用
-s参数,可以和 GDB 连接,进行内核代码的调试
下一章开始,我们将逐步添加硬件支持,让我们的操作系统拥有更多功能。
- https://wiki.osdev.org/Why_do_I_need_a_Cross_Compiler
- https://wiki.osdev.org/GCC_Cross-Compiler#Installing_Dependencies
- https://en.wikipedia.org/wiki/GNU_Compiler_Collection#Back_end
- https://en.wikipedia.org/wiki/Linker_(computing)
- https://www.geeksforgeeks.org/linker/#:~:text=Linker%20is%20a%20program%20in,data%20into%20a%20single%20file.
- https://wiki.osdev.org/Linkers
- https://wiki.osdev.org/Linker_Scripts
- https://wiki.osdev.org/LD
- https://wiki.osdev.org/GCC_Cross-Compiler
- https://wiki.osdev.org/Why_do_I_need_a_Cross_Compiler%3F#Background_information
- https://wiki.osdev.org/GCC
- https://wiki.osdev.org/OS_Specific_Toolchain
- https://wiki.osdev.org/Preparing_GCC_Build
- https://wiki.osdev.org/Porting_GCC_to_your_OS
- https://ftp.gnu.org/old-gnu/Manuals/ld-2.9.1/html_chapter/ld_3.html
- https://www.eecs.umich.edu/courses/eecs373/readings/Linker.pdf
- http://csapp.cs.cmu.edu/2e/ch7-preview.pdf
- https://stackoverflow.com/questions/17692428/what-is-ffreestanding-option-in-gcc
- https://gcc.gnu.org/onlinedocs/gcc/Standards.html
- https://gcc.gnu.org/onlinedocs/gcc/Option-Summary.html
- https://medium.com/datadriveninvestor/compilation-process-db17c3b58e62#:~:text=C%20is%20a%20compiled%20language,are%20by%20convention%20named%20with%20.
- https://www.geeksforgeeks.org/compiling-a-c-program-behind-the-scenes/
- https://www.geeksforgeeks.org/static-vs-dynamic-libraries/
- https://www.geeksforgeeks.org/working-with-shared-libraries-set-1/
- https://www.geeksforgeeks.org/working-with-shared-libraries-set-2/
- https://en.wikibooks.org/wiki/C_Programming/Basics_of_compilation
- https://en.wikipedia.org/wiki/Linker_(computing)
- https://en.wikipedia.org/wiki/Relocation_(computing)
- https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
- https://www.cs.virginia.edu/~evans/cs216/guides/x86.html
- https://www.tutorialspoint.com/assembly_programming/assembly_conditions.htm
- https://ftp.gnu.org/old-gnu/Manuals/ld-2.9.1/html_node/ld_3.html
- https://www.csie.ntu.edu.tw/~comp03/nasm/nasmdoc2.html
- https://www.tutorialspoint.com/makefile/index.htm
- https://www.gnu.org/software/make/manual/html_node/Automatic-Variables.html
- https://www.qemu.org/docs/master/system/gdb.html#:~:text=In%20order%20to%20use%20gdb,tell%20it%20to%20from%20gdb.
- https://www.rapidtables.com/code/linux/gcc/gcc-g.html
- https://stackoverflow.com/questions/54854128/use-of-o-c-in-makefile/54892804
- https://sourceware.org/gdb/wiki/How%20gdb%20loads%20symbol%20files#:~:text=symbol%2Dfile%20indicates%20that%20gdb,or%20vice%2Dversa%2C%20etc.
- http://nickdesaulniers.github.io/blog/2016/08/13/object-files-and-symbols/
- https://en.wikipedia.org/wiki/Object_file#:~:text=An%20object%20file%20is%20a,work%20like%20a%20shared%20library.
- https://stackoverflow.com/questions/7718299/whats-an-object-file-in-c