目录
- 回顾
- 今日目标
- BIOS 读取硬盘数据
- 32-Bit Protected Mode
- 总结
- 参考链接
回顾
上一篇文章,我们讨论了以下内容:
- Boot Sector 被 BIOS 加载到 0x7c00 的内存位置
- 用程序证实了 0x7c00 物理内存位置上,确实是我们的 Boot Sector 程序
- 寄存器分为通用寄存器,指针寄存器,段寄存器以及控制寄存器,我们分别列出了各个寄存器的名称及基本功能
- 用段寄存器替代
org指令来完成寻找 Boot Sector 前两个字节内容的任务 - 一个段中的内存寻址可以通过 [段寄存器:内存偏移量] 来完成
- 必要的汇编指令,如 jmp,cmp,times,pusha,popa等
今日目标
今天的目标,我们要告别 16-bit Real Mode,进入 32-bit Protected Mode。意味着我们离内核只有一步之遥了。
这篇文章中,我们即将要学习
- 如何读取磁盘上的数据,为读取内核代码做准备
- 什么是 GDT
- 如何在汇编中定义 GDT
- 如何切换到 32-bit Protected Mode
我将前两篇文章及今天这篇文章中涉及的代码,整理了一下,列在 这里。
我们开始吧。
BIOS 读取硬盘数据
硬盘数据的读取,需要在寄存器设置一系列的参数。有一些参数,有关硬盘的工作方式。所以,我们先来简单了解一下硬盘的必要知识。
硬盘
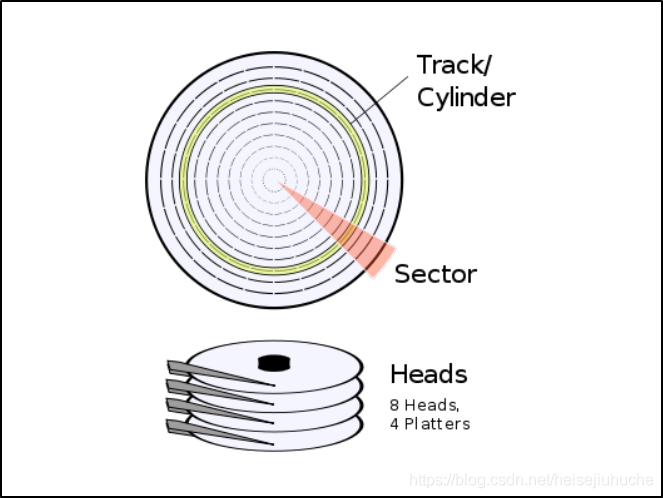
硬盘由盘片,和读写磁头组成。为了扩大容量,几张盘片,重叠在一起,由磁头来读写数据。由于盘片是有两面的,因此,一张盘片就有两个磁头,分别负责读取/写入该磁盘面上的数据。
引用书上的图片为例。
这是典型的机械硬盘的内部构造。

硬盘的盘片,是可以磁化的,一个比特的数据,磁化即为 1,非磁化即为 0。数据在盘片高速旋转时,由读写头读取和写入。
推荐大家看一下希捷的关于硬盘的视频。里面提到了 1个 bit 的实际物理大小,是 84 纳米(nanometer,也称毫微米)。
硬盘的物理构造,由专门的名词来描述。盘片叠加在一起,盘片上的每一圈,我们称之为磁道(Track),因为硬盘由多个盘片叠加组成,这些磁道,构成如一个圆柱体,我们称之为柱面(Cylinder)。读写装置,我们称之为磁头(Head)。每个盘面,被逻辑分成多个扇区(Sector),每个扇区通常是 512 个字节。
那么,在这样的物理构造下,我们要读取特定一个位置上的数据,就需要 3 个参数来确定。哪一个柱面(磁道),哪一个磁头,哪一个扇区。
这个 3D 坐标被称为 Cylinder-Head-Sector (CHS)地址。更多关于 CHS 的信息,可以阅读这篇 Wiki。
- Cylinder,即柱面,描述的是我们需要读取数据的在第几个磁道。
- Head,即磁头,描述的是我们需要的数据具体在哪一个盘面。
- Sector,即扇区,描述的是我们需要的数据在第几个扇区。
应用书上的图片作为例子。将 CHS 地址视觉化。
读取硬盘数据的参数
如同之前的文章中,我们要调用显示设备,在屏幕上输出字符,就要在 ah 中写入 0x0e,并触发中断。硬盘读写,也需要我们将相应的指令写入到寄存器,来告诉 BIOS 我们要读取的数据的位置和长度。
硬盘与与 CPU 有多种不同的连接总线,如 ATA/IDE,SATA,SCSI,USB。BIOS 为这些常见的设备提供了统一的指令。
我们将这些指令(包括寄存器中的参数和中断)列举在下面:
- AH 0x02 ; BIOS 读取磁盘扇区的模式(原书中写成了 al,有误)
- AL 0x5 ; 读取的扇区数(1 - 128)
- CH 0x3 ; 磁道/柱面 (0 - 1023)
- CL 0x4 ; 扇区(1-63)
- DH 0x1 ; 磁头(0 - 255)
- DL 0x0 ; 存储介质 (0 => 1 号软驱;1 => 2 号软驱;0x80 => 第 1 块硬盘;0x81 => 第 2 块硬盘)
- ES:BX ; 磁盘数据将被读取并写入到这个内存地址
- INT 0x13 ; 触发中断读取指定位置上指定长度的数据,并写入到内存的指定位置
读取操作完成之后,CPU 会设置几个返回值到寄存器,说明读取操作是否成功,我们可以做错误处理:
- AH ; 状态值,读取成功,或者发生了什么错误,所有磁盘读取状态值可以到这里查看
- AL ; 最终读取了多少个扇区
- CF ; 控制寄存器之一,称为 Carry Bit,硬盘数据读取成功为 0,错误为 1
更多关于每个参数的索引起始,以及索引范围的信息,可以阅读这篇 Wiki。
- AX 寄存器中,高位 AH 部分存储读取模式,低位 AL 部分存储要读取的扇区数。例:AH = 0x02,AL = 0x05,读取模式,读取 5 个扇区
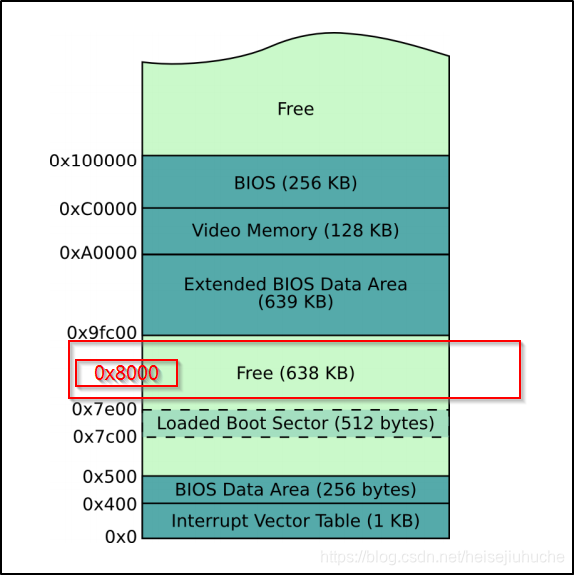
- BX 寄存器中,存储的是读取到的数据要被加载到内存地址的内存地址偏移量。例:BX = 0x8000,若 ES 为 0x0,读取的数据就被加载到 0x8000 的内存地址上
- CX 寄存器中,高位 CH 部分存储柱面信息,低位 CL 部分存储要读取第几扇区的数据。例:CH = 0x03,CL = 0x02,读取第 3 柱面,第 2 扇区
- DX 寄存器中,高位 DH 部分存储磁头信息,低位 DL 部分存储要读取第几块软驱或者硬盘的数据。例:DH = 0x01,DL = 0x0 读取第二号磁头,读取第一块存储介质
调用中断读取硬盘数据
记得上一篇中,我们给出的 boot sector 在内存中的位置,我们将选取 0x8000 作为加载我们磁盘数据的内存地址。它在我们的 boot sector 之后的空闲空间里。
我们将读取两个扇区的测试数据。
来看代码,磁盘读取的参数设置,在 read_from_disk.asm 中。
read_from_disk.asm
read_from_disk:
pusha
checking
push bx ; 之后打印出测试数据被加载到内存的位置
push dx
; 各个参数
mov ah, 0x02 ; 读取模式
mov al, dh ; 读取两个扇区的数据 (dead...beef...)
mov ch, 0x00 ; 从第 1 柱面开始读
mov cl, 0x02 ; 从第 2 扇区开始读 (第 1 个扇区是 boot sector)
mov dh, 0x00 ; 从第 1 磁头开始读
;mov dl, 0x00 ; 从第1 块存储介质开始读
int 0x013 ; 触发中断
mov bx, READ_START
call print
call print_nl
jc op_error ; 如果操作失败, CF(Carry Bit) 寄存器会被设置为 1, 如果 CF 寄存器被设置为 1,jc 就会跳转
pop dx
cmp al, dh
jne read_error
mov bx, READ_COMPLETE
call print
; 打印出测试数据被加载到哪里
pop bx
mov dx, bx
call print_hex
call print_nl
popa
ret
op_error:
; 错误信息
mov bx, OP_ERROR
call print
call print_nl
; 如果有错误发生,我们打印出错误码信息
mov dh, ah
call print_hex
; just hang the cpu on error
jmp disk_loop
read_error:
mov bx, READ_ERROR
call print
jmp disk_loop
disk_loop:
jmp $
READ_START: db "Reading start...", 0
READ_COMPLETE: db "Reading complete, data loaded to ", 0
OP_ERROR: db "Disk read error...", 0
READ_ERROR: db "Incorrect number of sectors read...", 0print_hex.asm
print_hex:
pusha
mov cx, 0 ; our indbx variable
; Strategy: get the last char of 'dx', then convert to ASCII
; Numeric ASCII values: '0' (ASCII 0x30) to '9' (0x39), so just add 0x30 to byte N.
; For alphabetic characters A-F: 'A' (ASCII 0x41) to 'F' (0x46) we'll add 0x40
; Then, move the ASCII byte to the correct position on the resulting string
hex_loop:
cmp cx, 4 ; loop 4 times
je end
; 1. convert last char of 'dx' to ascii
mov ax, dx ; we will use 'ax' as our working register
and ax, 0x000f ; 0x1234 -> 0x0004 by masking first three to zeros
add al, 0x30 ; add 0x30 to N to convert it to ASCII "N"
cmp al, 0x39 ; if > 9, add extra 7 to represent 'A' to 'F'
jle step2
add al, 7 ; 'A' is ASCII 65 instead of 58, so 65-58=7
step2:
; 2. get the correct position of the string to place our ASCII char
; bx <- base address + string length - indbx of char
mov bx, HEX_OUT + 5 ; base + length, starts last last char of HEX_OUT
sub bx, cx ; our indbx variable
mov [bx], al ; copy the ASCII char on 'al' to the position pointed by 'bx'
ror dx, 4 ; 0x1234 -> 0x4123 -> 0x3412 -> 0x2341 -> 0x1234
; increment indbx and loop
add cx, 1
jmp hex_loop
end:
; prepare the parameter and call the function
; remember that print receives parameters in 'bx'
mov bx, HEX_OUT
call print
popa
ret
HEX_OUT:
db '0x0000',0 ; reserve memory for our new stringprint.asm
print:
pusha
start:
mov al, [bx] ; 'bx' is the base address for the string
cmp al, 0
je done
mov ah, 0x0e
int 0x10 ; 'al' already contains the char
add bx, 1 ; print next char
jmp start
done:
popa
ret
; print new line
print_nl:
pusha
mov ah, 0x0e
mov al, 0x0a ; newline char
int 0x10
mov al, 0x0d ; carriage return
int 0x10
popa
retboot_sect_main.asm
[org 0x7c00]
; 我们将利用栈保存一些寄存器的值,所以将栈的内存位置设置在空闲区域
mov ax, 0x8000
mov bp, ax
mov sp, bp
; 测试数据会被加载到 [ES:BX] => 0x8000
mov ax, 0x0
mov es, ax
mov bx, 0x9000
; 读取两个扇区的数据,dh 这里用来传递 0x2 这个数据
mov dh, 0x2
; 开始读取
call read_from_disk
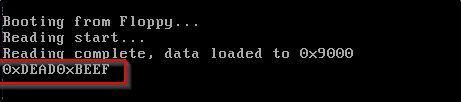
; 打印第 2 扇区第一个字 => 0xdead
mov dx, [es:bx]
call print_hex
; 打印第 3 个扇区第一个字 => 0xbeef
mov dx, [es:bx + 512]
call print_hex
jmp $
%include "print.asm"
%include "print_hex.asm"
%include "read_from_disk.asm"
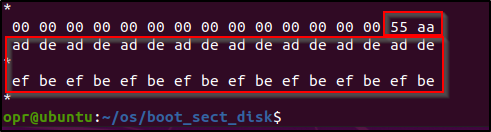
times 510 - ($ - $$) db 0x0
dw 0xaa55
; 写入 512 个字节到第 2 扇区(第 1 扇区是 boot sector)
times 256 dw 0xdead
; 写入 512 个字节到第 3 扇区
times 256 dw 0xbeef在 boot_sect_main.asm 中,我们分别读取了第二和第三个扇区的前两个字节,可以看到结果如下。
我们可以用 od 命令查看 bin 文件中的内容,看到紧接着我们的 boot sector,写入了我们的测试数据。
大家可以尝试修改代码,加载测试数据到不同的内存地址,观察程序的变化。
现在,我们已经具备加载内核的能力。下面,我们告别 16-bit Real Mode,开启 32-bit Protected Mode。
32-Bit Protected Mode
16-bit Real Mode 以下称 16 位模式, 32-Bit Protected Mode 以下称 32 位模式。
首先,经过前两篇文章的学习,我们已经很熟悉 16 位模式了。现在,我们要思考一下为什么还需要切换到 32 位模式,它和 16 位模式有什么区别。
接着,我们要学习 32 位模式中最重要的概念,全局描述符(Global Descriptor Table)。
最后,我们学习怎么在汇编中定义 GDT,并切换到 32 位模式。
关于 32-Bit Protected Mode
在切换操作之前,我们必须先了解一下 32 位模式。
什么是 32-bit Protected Mode?
Protected Mode,保护模式,是自 80286 以来的现代 CPU 的主要工作模式。
32 位模式加入了虚拟内存的概念,并且加强了内存读写保护,提供了通过 Rings 限制可用指令的能力。
总而言之,32 位模式向着更加高级,更加安全的方向发展,为现代操作系统提供了一个更好的运行环境。
为什么我们需要 32-bit Protected Mode?
我们从 16 位模式切换到 32 位模式,有两个最主要的目的。
- 第一,为了完全释放 CPU 的能力
- 第二,为了更好地理解硬件的内存保护机制
我们不能容忍那可怜的 1MB 内存,不能容忍我们程序的内存毫无保护,所以,32 位模式势在必行。
32-bit Protected Mode vs 16-bit Real Mode
到了 32 位模式之后所发生的变化总结如下:
- 寄存器扩展到了 32-bit,之后,寄存器的使用都要加上
e,意思是extended,例如:mov eax, 0x80808080 - 通用寄存器增加了两个,FS 和 GS
- 内存分段的技术更加高效,同时也更加复杂
- 我们可以防止一个段中的代码被执行
- CPU 支持虚拟内存和分页,用户程序将会以分页的形式在磁盘和内存之间进行切换(swapping)
- 中断的处理也更加的高级
32 位模式下的字符打印
在继续下面的内容之前,我们必须先做一点代码上的调整。能够打印字符对于程序的调试是很重要的,所以,我们现在要将 16 位模式下的打印字符的代码,调整到 32 位可用。在调整代码之前,我们需要先对 32 位模式下的底层调用有所了解,才能顺利在 32 位模式下打印字符。
告别 BIOS
BIOS 下的中断和系统调用,是专门为 16 位模式设计的,因此,在 32 位模式下不可用。书中提到,有办法可以暂时切换回 16 位模式去使用 BIOS 的系统调用,但是这没有意义,十分复杂,也违背我们要切换到 32 位的初衷。
那么,我们必须丢弃 BIOS,重新调整我们的思路去适应 32 位模式。
32 位模式下的显示设备调用
这里要说明的是 32 位模式下,关于显示设备调用需要理解的一些概念。
Memory-Mapped Device(Memory-Mapped I/O)
计算机的外围设备,分为 Memory-Mapped(内存映射) 和 Port-Mapped(端口映射)两种。我们这里讨论的显示设备,是 Memory-Mapped Device(暂译为内存映射设备)的一种。
计算机外围设备,都以某种方式连接至 CPU,他们都与 CPU 有输入输出的操作。因此,外围设备的输入输出操作被统称为 Memory/Port-Mapped I/O。
内存映射设备使用同一内存空间来记录数据内存地址与设备内存地址。这是我总结的,原文是 “Memory-mapped I/O uses the same address space to address both memory and I/O devices.”。可以这样理解, CPU 访问设备内存上的数据时,其实就是在访问设备本身。有这样特征的设备,就被称为 Memory-Mapped Device。
例如显示设备,我们只需要往设备内存中写入数据,就可以在屏幕上展示这些数据。
所以,接下来要讲到的在 32 位模式下打印字符,我们只需要 CPU 去访问特定的显示设备内存(Video Memory),即可完成显示设备调用,打印字符到屏幕。
VGA 模式(Video Graphics Array)
显示设备有两种模式可以设置:
- 文本模式(text mode)
- 图形模式(graphics mode)
在计算机启动的时候,无论计算机上有多么高级的显示设备(RTX 2080Ti 😄),都必须从 Video Graphics Array(VGA)标准文本模式开始。书中讨论的是,VGA 标准文本模式的一种,它的特点是:
- 以行列模式显示字符
- 有效像素为 720x400
- 可以显示 80x25 个字符
- 每个字符 9x16 像素大小
在 VGA 模式下,我们不需要对每个像素进行操控,因为就像上面所说,字符的信息(9x16像素)已经存储在显示设备的内存中。我们称每个字符信息为一个字符单元(character cell)。
在内存中,每个字符单元用 2 个字节 表示。第一个字节代表字符的 ASCII 码,第二个字节代表 该字符显示时的属性,如背景色,前景色,或者是否该闪烁。
VGA 模式内存
前文我们说到了显示设备是内存映射设备,因此,我们要显示字符,就必须在设备内存的位置上,写入相应的值。
这个设备的内存地址比较固定,通常都在 0xb8000。
另外,前文说到 VGA 模式是行列模式(80x25),但是内存是线性的,因此,我们还有一个公式,用于计算行列上的字符的内存地址。
0xb8000 + 2 * (row * 80 + col)例如第 2 行第 3 列的内存地址应该是 0xb8000 + 2 * (2 * 80 + 3) => 0xb8206。
这个公式以后会用到。暂做记录。
32-bit Protected Mode 输出字符
学习了这么多,是时候写段代码了。
下面的代码会在屏幕的左上角打印出 HelloWorld
pm_print.asm
; 常量定义
VIDEO_MEMORY equ 0xb8000 ; VGA 设备内存地址
WHITE_ON_BLACK equ 0x0f ; 显示属性,白色前景,黑色背景
; 打印 EDX 中的字符串
print_string_pm:
pusha
mov edx, VIDEO_MEMORY ; Set edx to the start of vid mem.
print_string_pm_loop:
mov al, [ebx] ; Store the char at EBX in AL
mov ah, WHITE_ON_BLACK ; Store the attributes in AH
cmp al, 0 ; if (al == 0) , 字符串结束
je print_string_pm_done
mov [edx], ax ; 将字符和属性写入 EDX 指向的内存地址
add ebx, 1 ; 指向下一个字符
add edx, 2 ; 指向设备内存的下一个字符单元(1 个字符单元 2 个字节)
jmp print_string_pm_loop ; 循环打印
print_string_pm_done:
popa
retpm_main.asm
org 0x7c00
mov ebx, HELLO_WORLD
call print_string_pm
jmp $
%include "pm_print.asm"
HELLO_WORLD: db "HelloWorld", 0
times 510 - ($ - $$) db 0
dw 0xaa55注意,在测试打印代码的时候,不要任何文件中放置 bits 32 指令,我们还没有做切换操作,否则会没有任何显示。
测试结果如下,屏幕左上角打印出字符串 HelloWorld。
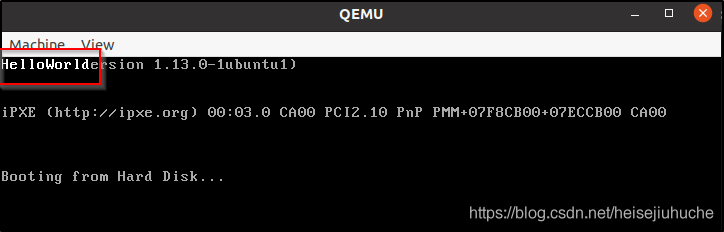
通过测试代码,在 print_string_pm_loop 方法中,我们往 edx 所在的显示设备内存写入任意字符(mov [edx], ax),屏幕上就会显示出相应的字符,这就是内存映射设备的工作方式。
全局描述符(GDT)
现在,我们已经知道了 32 位模式下打印字符的原理。我们接着了解最后一个概念,全局描述符(Global Descriptor Table)。
什么是 GDT 及 GDT 的作用
全局描述符,Global Descriptor Table(GDT)让 CPU 在 32 位模式下实现像 16 位模式一样的内存寻址。它是各类描述符的统一集中。它不仅包括段描述,还有 Task State Segment 描述符,Local Descriptor Table,Call State Structures等。
我们这里着重要讨论的,是段描述符(Segement Descriptor)。
回忆在 16 位模式中,内存寻址的公式是:
段选择符 * 10H + 内存偏移量在我们切换到 32 位模式之后,虽然这样的 段地址 + 偏移量 的逻辑没有变,但是实现方式完全不同。
之前的 段选择符(Segment Selector),现在指向的是前面提到的 段描述符(Segment Descriptor)。
与段内存相关的段内存描述符,是段内存的元信息,包含了段内存空间的基址,大小,访问权限等。这个 8 个字节的数据描述了 32 位模式下的段内存的如下几个属性:
- 32 位的段内存基址(Base Address),定义了该段内存的起始物理内存地址
- 20 位的段空间(Segment Limit),定义了该段内存的空间大小
- 另外的一些标识位(Flags),定义了该段内存的其他属性,如运行权限,是否只读等
我们引用书上的图片来看一下 GDT 的结构。
在之后用代码定义完 GDT 之后,我会将 GDT 的各个位拿出来梳理。
下图中,红色是 GDT 的前 4 个字节,绿色是后 4 个字节。我们最关注的两个属性,基址和段空间大小可以很清楚看到分布在 GDT 的结构中。只是位置很奇怪。OS-From-Scratch 的作者并不清楚为什么如此分配 bit 给这两个属性,东一点,西一点,可能跟 CPU 的设计有关。

以下是书上对于每个属性的简单解释:


Basic Flat Model
虽然定义很复杂,但是 Intel 给出了一个最简单的 GDT 模型,叫做 Basic Flat Model。这个模型只定义两个相叠加的段内存(段内存叠加我们在下一篇中讲解),共同覆盖 4GB 的物理内存空间。这两个段内存,一个是 代码段(Code Segment),一个是是 数据段(Data Segment)。
在这个简单的模型下,两个段内存间仍然是没有内存保护机制的,同时,也无法使用虚拟内存的分页特性。使用这样简单的模型,只为了让我们过渡到 32 位模式,以便我们能用高级语言(C)在后期更高效地修改 GDT。
定义 GDT
要注意的是,CPU 要求 GDT 的最开始是一个 null descriptor,是一个 8 个字节的 0,硬性规定,我们只能照做。
另外,CPU 必须知道我们的 GDT 的长度。不过我们不会将 GDT 的起始地址直接交给 CPU,而会将一个更加简单的数据交给 CPU,这个数据结构叫做 GDT Descriptor(相当于 GDT 的元数据,用来描述 GDT)。
GDTD 是一个 6 字节结构,包含:
- GDT 的长度(16 位)
- GDT 的基址(32 位)
现在,我们会用 db,dw,dd 指令在段描述符中写入必要的数据。
代码中使用 10001100b 这样的形式,来直接写入二进制;使用 dw 来写入 2 个字节;使用 dd 来写入 4 个字节(double word)。
pm_32bit_gdt.asm
; GDT
gdt_start :
gdt_null: ; 定义 gdt 起始的 null descriptor,8 个字节
dd 0x0
dd 0x0
gdt_code: ; 定义 gdt code 段
dw 0xffff ; Limit ( bits 0 -15)
dw 0x0 ; Base ( bits 0 -15)
db 0x0 ; Base ( bits 16 -23)
db 10011010b ; 1st flags , type flags
db 11001111b ; 2nd flags , Limit ( bits 16 -19)
db 0x0 ; Base ( bits 24 -31)
gdt_data: ; 定义 gdt data 段
dw 0xffff ; Limit ( bits 0 -15)
dw 0x0 ; Base ( bits 0 -15)
db 0x0 ; Base ( bits 16 -23)
db 10010010b ; 1st flags , type flags
db 11001111b ; 2nd flags , Limit ( bits 16 -19)
db 0x0 ; Base ( bits 24 -31)
gdt_end: ; 这个 label 用于计算 GDT 的长度,交给接下来的 GDTD 使用
; GDT descriptior
gdt_descriptor :
dw gdt_end - gdt_start - 1 ; GDT 的长度,总是实际代码长度 - 1(因为不能定义长度为 0 的 GDT)
dd gdt_start ; GDT 的基址
; 定义两个常量,分别代表代码段和数据段的内存地址偏移量
CODE_SEG equ gdt_code - gdt_start
DATA_SEG equ gdt_data - gdt_start我们具体看一下两个 GDT 的具体数据:
GDT Code:
0000 0000 1100 1111 1001 1010 0000 0000 0000 0000 0000 0000 1111 1111 1111 1111
【1】 【2】 【3】 【4】 【5】 【6】【1】基址最高位 8 位,全部为 0
【2】4 个第二标识位 1100,4 个 Limits 最高位 1111
【2-1】4 个第二标识位为:|G|D/B|L|AVL
【2-1-1】G:Granularity 设置为1,就会将我们的 limit 左移 12 位(十进制 4096,16 进制 1000),来完成 4GB 的寻址;这里就是为什么我们说 32 位模式的寻址逻辑,和 16 位模式一样,只是实现方式不同;这里设置为 1
【2-1-2】DB:Default Operation Size,0 代表 16-bit Segment,1 代表 32-bit Segment,这里设置为 1
【2-1-3】L:是否是 64-bit Code Segment,1 代表是,0 代表不是,我们是 32-bit,这里设置为 0
【2-1-4】AVL:是否可被系统程序使用,这里设置为 0
【2-2】:4 个 Limits 最高位,这里设置为 1111
【3】4 个第一标识位 1001,Type 标识位 1010
【3-1】4 个第一标识位为 |P|DPL|S,DPL 占 2 个 bit
【3-1-1】P:Segemnt Present,设置为 0,则段不可用,因此,这里设置为 1
【3-1-2/3】DPL:Descriptor Privilege Level,本文在 什么是 32-bit Protected Mode? 中提到的 Ring 就是这里的权限等级,0 为最高级,这里设置为 00
【3-1-4】S:Descriptor Type,这个描述符的种类,0 为系统,1 为代码或者数据,这里设置为 1
【3-2】Type 类型,4 个 bit
【3-2-1】类型位:0 为数据,1 为代码,这里设置为 1
【3-2-2】Conforming:如果设置为 0,其他低权限段内存中的代码无法调用本段中的代码,这是内存保护的原型,这里设置为 0
【3-2-3】Readable/Writable:Readable 针对代码段,Writable 针对数据段;代码段不可写,数据段不可读;这里,1 为可读,0 为只可执行,设置为 1 允许我们读取定义在代码中的常量,这里设置为 1
【3-2-4】Accessed:虚拟内存以及 debugging 使用,这里设置为 0
【4】【5】基地址低 24 位,全部为 0,因此基地址为 32 个 0
【6】Limit 最低 16 位,全部位 1,因此 Limit 为 1111 1111 1111 1111 1111(20 位)
GDT Data 只是将上述 【3-2-1】设置位 0,代表数据,其余位全部一样。
GDT 更多的内容,大家可以看 这篇文章。
这就是 GDT 的全部内容。
接下来,我们将在最后一步,切换到 32 位模式的操作中,使用定义好的 GDT。
切换到 32-Bit Protected Mode
切换的操作很直观,我们来看一下切换之前的几个必要步骤:
- cli 禁用中断,如果还有中断被触发,将被 CPU 全部忽略(直到中断被手动恢复)
- lgdt [gdt_descriptor] 将 GDTD 交给 CPU(前文说过,我们不会将 GDT 直接交给 CPU,而是将 GDTD 交给 CPU)
- 设置 cr0 寄存器的第一个 bit 为 1
- 做一次 far jump,jmp <段地址>:<内存偏移量>,让 CPU pipline 中的指令全部清空(将不同阶段的指令全部执行完)
一旦切换到 32 位模式,首先要做几件事情,来确保在 32 位模式下的内存寻址和指令执行不会出错:
- 使用 bits 32 指令来告诉 assembler 现在开始所有的指令要以 32 位模式来编译
- 设置其他段寄存器的地址,指向 GDT 中定义的新的数据段
- 更新栈的地址
Instruction Pipelining
我们简单介绍一下 Instruction Pipelining(以下简称 IP) 以及 Pipeline Flushing(以下简称 PF)。这是在单 CPU 下实现指令级并发的技术。CPU 是由控制单元,逻辑控制,寄存器等器件构成,pipelining 技术将合理安排这些 CPU 内部器件的工作,降低闲置时间,实现指令的并行执行,将效率最大化。
x86 CPU 的指令执行步骤如下:
- 读取指令
- 指令解码及寄存器访问
- 执行
- 访问内存
- 结果写回寄存器
每一个步骤,被称为一个 stage(阶段)。
IP 技术使得指令的执行并行,也就产生不同指令在不同阶段的情况。比如指令 A 已经到了解码阶段,指令 B 在读取阶段,而指令 C 已经到执行阶段。
记得前几年英特尔 CPU 的 漏洞 跟 IP 技术是有关的。
现在的情况是,如果我们切换到了 CPU,但是 CPU 的 pipeline 中还有未执行完的某个阶段的指令,如果该指令是需要在 16 位模式下执行,而我们已经切换到了 32 位模式,那么 CPU 就会崩溃。
因此,我们在切换到 32 位模式下,一定要做一个操作将 pipeline 中的指令全部清空(Pipeline Flushing 让 CPU 在切换之前将未执行完的指令全部执行完)。
我没有找到太多有关 PF 的资料。大家可以看一下 Intel Developer Manual 上对于模式切换的说明。

模式切换
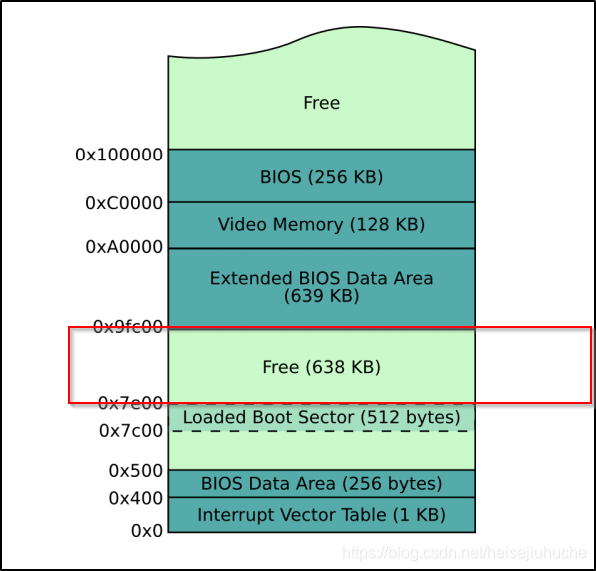
进入 32 位模式之后,我们的栈空间会被设置在这个空余内存空间内。
pm_32bit_switch.asm
[bits 16]
switch_to_pm:
cli ; 禁用中断
lgdt [gdt_descriptor] ; 将 GDTD 内容交给 CPU
mov eax, cr0
or eax, 0x1
mov cr0, eax ; 这 3 步,设置 cr0 寄存器的第一个 bit,由于不能直接写入,借助 eax 传递
jmp CODE_SEG:init_pm ; far jump,清空 CPU Pipeline,接下来就是 32 位模式
[bits 32] ; 进入 32 位模式
init_pm:
mov ax, DATA_SEG ; 更新其他段寄存器,指向我们的数据段
mov ds, ax
mov ss, ax
mov es, ax
mov fs, ax
mov gs, ax
mov ebp, 0x8000; 更新栈地址
mov esp, ebp
call BEGIN_PM ; 打印信息pm_32bit_switch_main.asm
[org 0x7c00]
mov bp, 0x800 ; 指向上述代码中的新的栈(bp * 10H + 0x0 = 0x8000)
mov sp, bp
mov bx, MSG_REAL_MODE
call print ; 输出在在 BIOS 信息之后
call switch_to_pm ; 开始切换模式
%include "print_16bit.asm"
%include "pm_32bit_gdt.asm"
%include "pm_32bit_print.asm"
%include "pm_32bit_switch.asm"
[bits 32]
BEGIN_PM: ; after the switch we will get here
mov ebx, MSG_PROT_MODE
call print_string_pm ; 打印在屏幕左上角
jmp $
MSG_REAL_MODE db "Started in 16-bit real mode", 0
MSG_PROT_MODE db "Loaded 32-bit protected mode", 0
; bootsector
times 510 - ($ - $$) db 0
dw 0xaa55切换及打印信息所需所有代码,在 32Bit Protected Mode Switch。
运行结果如下,成功切换到 32 位模式。

总结
- 读取硬盘所需的参数设置,硬盘数据的地址由 CHS 提供,我们需要将柱面,磁头,扇区信息写入相应的寄存器
- 读取硬盘的测试数据并打印
- 32 位模式提供虚拟内存,分页等更加灵活高效的内存管理模式,同时增加了内存寻址的空间,寄存器也从 16 位扩展到了 32 位
- 无论计算机的显示设备多么高级,在计算机启动时,都处于 VGA 模式
- VGA 文本模式的一种,是 80x25 的行列模式,每个字符的像素大小是 9x16
- VGA 模式下,一个字符的在内存中的位置被称为字符单元
- 显示设备是内存映射设备,我们在显示设备的内存地址写入信息,就可以显示在屏幕上
- 全局描述符是 32 位模式下内存寻址重要信息
- 在 32 位模式下,段寄存器指向的不是段内存的基址,而是 GDT 中的段描述符
- 段描述符包含了段内存的基址,大小,权限等信息
- 切换到 32 位之前,我们必须定义 GDT 和 GDTD(GDT Descriptor)
- 我们还需要禁用中断,将 GDTD 交给 CPU,设置 cr0 寄存器的第一个 bit,做一个 far jump 清空 CPU pipeline
- 切换到 32 位之后,要在代码中使用 bits 32 来让 assembler 以 32 位模式编译指令,另外,我们需要将其他段寄存器指向我们新的段内存,并更新栈的地址到空闲内存地址
这是一个需要耐心的漫长的旅程。我们终于可以在下一章,拉开内核的序幕,并转向高级语言 C。
- https://wiki.osdev.org/Protected_Mode#:~:text=On%2080386s%20and%20later%2C%20the,available%20instruction%20set%20via%20Rings.
- https://wiki.osdev.org/Security#Rings
- https://en.wikipedia.org/wiki/INT_13H
- https://stanislavs.org/helppc/int_13-2.html
- https://stanislavs.org/helppc/int_13-1.html
- https://wiki.osdev.org/BIOS
- https://en.wikipedia.org/wiki/Cylinder-head-sector
- https://en.wikipedia.org/wiki/Virtual_memory
- https://en.wikipedia.org/wiki/Paging
- https://en.wikipedia.org/wiki/Memory-mapped_I/O
- https://en.wikipedia.org/wiki/Video_Graphics_Array#Standard_text_modes
- https://wiki.osdev.org/Printing_To_Screen
- http://3zanders.co.uk/2017/10/16/writing-a-bootloader2/
- https://en.wikipedia.org/wiki/Global_Descriptor_Table
- https://wiki.osdev.org/Global_Descriptor_Table
- https://wiki.osdev.org/GDT_Tutorial#What_should_I_put_in_my_GDT.3F
- https://en.wikibooks.org/wiki/X86_Assembly/Global_Descriptor_Table
- https://www.cs.umd.edu/~meesh/cmsc411/website/saltz/cs412/lect3.html
- https://en.wikipedia.org/wiki/Protection_ring
- http://tuttlem.github.io/2014/07/11/a-gdt-primer.html#:~:text=gdt_tab%20starts%20with%20the%20length,that%20has%20a%20zero%20length.
- https://en.wikipedia.org/wiki/Instruction_pipelining
- https://en.wikipedia.org/wiki/Central_processing_unit
- https://electronics.stackexchange.com/questions/153735/what-is-pipeline-flushing-in-microprocessors
- https://www.computerhope.com/jargon/p/pipeline-flush.htm
- https://en.wikipedia.org/wiki/Meltdown_(security_vulnerability)
- http://faydoc.tripod.com/cpu/jmp.htm
- https://en.wikipedia.org/wiki/Pipeline_stall
- http://qcd.phys.cmu.edu/QCDcluster/intel/vtune/reference/vc145.htm#:~:text=Far%20jump%2D%2DA%20jump,to%20as%20an%20intersegment%20jump.&text=When%20executing%20a%20near%20jump,specified%20with%20the%20target%20operand.
- https://stackoverflow.com/questions/29430762/what-is-the-difference-if-any-between-long-and-far-jumps-in-assembly
- https://stackoverflow.com/questions/5757866/what-does-short-jump-mean-in-assembly-language#:~:text=Short%20jumps%20(and%20near%20calls,from%20the%20address%20of%20the
- https://software.intel.com/content/dam/develop/public/us/en/documents/325462-sdm-vol-1-2abcd-3abcd.pdf